Chapter 5 Reliability
The focus of this lecture is the assessment of reliability. We start by defining classical test theory and examining several forms of reliability. While the majority of our time is spent considering estimates of internal consistency, we also review retest reliability and inter-rater reliability.
5.2 Defining Reliability
5.2.1 Begins with Classical Test Theory (CTT)
CTT is based on Spearman’s (1904) true-score model where:
- an observed score consists of two components – a true component and an error component
- X = T + E
- X = the fallible, observed/manifest score, obtained under ideal or perfect conditions of measurement (these conditions never exist);
- T = the true/latent score (that will likely remain unknown); and
- E = random error
- In CTT, we assume that the traits measured are constant and the errors random.
- Therefore, the mean of measurement errors for any individual (upon numerous repeated testing) would be zero.
- That said, in CTT, the true score would be equal to the mean of the observed scores over an indefinite number of repeated measures.
- Caveat: this is based on the assumption that when individuals are repeatedly measured, their true scores remain unchanged.
- In classic test theory, true score can be estimated over multiple trials. However, if errors are systematically biased, the true score will remain unknown.
5.2.2 Why are we concerned with reliability? Error!
Measurements are imperfect and every observation has some unknown amount of error associated with it. There are two components in error:
- random/unsystematic: varies in unpredictable and inconsistent ways upon repeated measurements; sources are unknown
- systematic: recurs upon repeated measurements reflecting situational or individual effects that, theoretically, could be specified.
Correlations are attenuated (i.e., smaller than) from the true correlation if the observations contain error. Knowing the reliability of an instruments allows us to:
- estimate the degree to which measured at one time and place with one instrument predict scores at another time and/or place and perhaps measured with a different instrument
- estimate the consistency of scores
- estimate “…the degree to which test scores are free from errors of measurement” (APA, 1985, p. 19)
Figure 7.1a in Revelle’s chapter illustrates the attenuation of the correlation between the variables p and q as a function of reliability.
- circles (latent variables [LV]) represent the true score
- observed/measured/manifest variables are represented by squares, and each has an associated error; not illustrated are the random and systematic components of error
- a true score is composed of a measured variable and its error
- the relationship between the true scores would be stronger than the one between the measured variables
- moving to 7.1b in Revelle’s chapter, the correlation between LV p and the observed ’’ can be estimated from the correlation of p’ with a parallel test (this is the reliability piece)
Figure 7.2 in Revelle’s Chapter 7 (n.d.) illustrates the conceptual effect of reliability on the estimation of a true score. The figure is meant to demonstrate that when error variances are small and reliability is greater, the variance of the true scores more closely approximates that of observed scores.
5.2.3 The Reliability Coefficient
The symbol for reliability, \(r_{xx}\), sums up the big-picture definition that reliability is the correlation of a measure with itself. There are a number of ways to think about it:
- a “theoretical validity” of a measure because it refers to a relationship between observed scores and scores on a latent variable or construct,
- represents the fraction of an observed score variance that is not error,
- ranges from 0-1
- 1, when all observed variance is due to true-score variance; there are no random errors,
- 0, when all observed variance is due to random errors of measurement,
- represents the squared correlation between observed scores and true scores,
- the ratio between true-score variance and observed-score variance (for a formulaic rendition see (Pedhazur & Schmelkin, 1991)),
\[r_{xt}^{2}=r_{xx} =\frac{\sigma_{2}^{t}}{\sigma_{2}^{x}}\] where \(r_{xt}^{2}\) is the proportion of variance between observed scores (t + e) and true scores (t); its square root is the correlation
\(r_{xx}\) is the reliability of a measure
\({\sigma_{2}^{t}}\) is the variance of true scores
\({\sigma_{2}^{x}}\) is the variance of observed scores
- The reliability coefficient is interpreted as the proportion of systematic variance in the observed score.
- .8 means that 80% of the variance of the observed scores is systematic;
- .2 (e.g., 1.00 - .8)is the proportion of variance due to random errors;
- the reliability coefficient is population specific.
To restate the first portion of the formula: although reliability is expressed as a correlation between observed scores, it is also the ratio of reliable variance to total variance.
5.3 Research Vignette
The research vignette for this lesson is the development and psychometric evaluation of the Perceptions of the LGBTQ College Campus Climate Scale (Szymanski & Bissonette, 2020). The scale is six items with responses rated on a 7-point Likert scale ranging from 1 (strongly disagree) to 7 (strongly agree). Higher scores indicate more negative perceptions of the LGBTQ campus climate. Szymanski and Bissonette (2020) have suggested that the psychometric evaluation supports using the scale in its entirety or as subscales. Each item is listed below with its variable name in parentheses:
- College response to LGBTQ students:
- My university/college is cold and uncaring toward LGBTQ students. (cold)
- My university/college is unresponsive to the needs of LGBTQ students. (unresponsive)
- My university/college provides a supportive environment for LGBTQ students. (unsupportive)
- this item must be reverse-scored
- LGBTQ Stigma:
- Negative attitudes toward LGBTQ persons are openly expressed on my university/college campus. (negative)
- Heterosexism, homophobia, biphobia, transphobia, and cissexism are visible on my university/college campus. (heterosexism)
- LGBTQ students are harassed on my university/college campus. (harassed)
A preprint of the article is available at ResearchGate. Below is the script for simulating item-level data from the factor loadings, means, and sample size presented in the published article.
Because data is collected at the item level (and I want this resource to be as practical as possible, I have simulated the data for each of the scales at the item level.
Simulating the data involved using factor loadings, means, and correlations between the scales. Because the simulation will produce “out-of-bounds” values, the code below rescales the scores into the range of the Likert-type scaling and rounds them to whole values.
Five additional scales were reported in the Szymanski and Bissonette article (2020). Unfortunately, I could not locate factor loadings for all of them; and in two cases, I used estimates from a more recent psychometric analysis. When the individual item and their factor loadings are known, I assigned names based on item content (e.g., “lo_energy”) rather than using item numbers (e.g., “PHQ4”). When I am doing psychometric analyses, I prefer item-level names so that I can quickly see (without having to look up the item names) how the items are behaving. While the focus of this series of chapters is on the LGBTQ Campus Climate scale, this simulated data might be useful to you in one or more of the suggestions for practice (e.g., examining the psychometric characteristics of one or the other scales). The scales, their original citation, and information about how I simulated data for each are listed below.
- Sexual Orientation-Based Campus Victimization Scale (Herek, 1993) is a 9-item item scale with Likert scaling ranging from 0 (never) to 3 (two or more times). Because I was not able to locate factor loadings from a psychometric evaluation, I simulated the data by specifying a 0.8 as a standardized factor loading for each of the items.
- College Satisfaction Scale (Helm et al., 1998) is a 5-item scale with Likert scaling ranging from 1 (strongly disagree) to 7 (strongly agree). Higher scores represent greater college satisfaction. Because I was not able to locate factor loadings from a psychometric evaluation, I simulated the data by specifying a 0.8 as a standardized factor loading for each of the items.
- Institutional and Goals Commitment (Pascarella & Terenzini, 1980) is a 6-item subscale from a 35-item measure assessing academic/social integration and institutional/goal commitment (5 subscales total). The measure had with Likert scaling ranging from 1 (strongly disagree) to 5 (strongly agree). Higher scores on the institutional and goals commitment subscale indicate greater intentions to persist in college. Data were simulated using factor loadings in the source article.
- GAD-7 (Spitzer et al., 2006) is a 7-item scale with Likert scaling ranging from 0 (not at all) to 3 (nearly every day). Higher scores indicate more anxiety. I simulated data by estimating factor loadings from Brattmyr et al. (2022).
- PHQ-9 (Kroenke et al., 2001) is a 9-item scale with Likert scaling ranging from 0 (not at all) to 3 (nearly every day). Higher scores indicate higher levels of depression. I simulated data by estimating factor loadings from Brattmyr et al. (2022).
#Entering the intercorrelations, means, and standard deviations from the journal article
Szymanski_generating_model <- '
#measurement model
CollegeResponse =~ .88*cold + .73*unresponsive + .73*supportive
Stigma =~ .86*negative + .76*heterosexism + .71*harassed
Victimization =~ .8*Vic1 + .8*Vic2 + .8*Vic3 + .8*Vic4 + .8*Vic5 + .8*Vic6 + .8*Vic7 + .8*Vic8 + .8*Vic9
CollSat =~ .8*Sat1 + .8*Sat2 + .8*Sat3 + .8*Sat4 + .8*Sat5
Persistence =~ .69*graduation_importance + .63*right_decision + .62*will_register + .59*not_graduate + .45*undecided + .44*grades_unimportant
Anxiety =~ .851*nervous + .887*worry_control + .894*much_worry + 674*cant_relax + .484*restless + .442*irritable + 716*afraid
Depression =~ .798*anhedonia + .425*down + .591*sleep + .913*lo_energy + .441*appetite + .519*selfworth + .755*concentration + .454*too_slowfast + .695*s_ideation
#Means
CollegeResponse ~ 2.71*1
Stigma ~3.61*1
Victimization ~ 0.11*1
CollSat ~ 5.61*1
Persistence ~ 4.41*1
Anxiety ~ 1.45*1
Depression ~1.29*1
#Correlations
CollegeResponse ~~ .58*Stigma
CollegeResponse ~~ -.25*Victimization
CollegeResponse ~~ -.59*CollSat
CollegeResponse ~~ -.29*Persistence
CollegeResponse ~~ .17*Anxiety
CollegeResponse ~~ .18*Depression
Stigma ~~ .37*Victimization
Stigma ~~ -.41*CollSat
Stigma ~~ -.19*Persistence
Stigma ~~ .27*Anxiety
Stigma ~~ .24*Depression
Victimization ~~ -.22*CollSat
Victimization ~~ -.04*Persistence
Victimization ~~ .23*Anxiety
Victimization ~~ .21*Depression
CollSat ~~ .53*Persistence
CollSat ~~ -.29*Anxiety
CollSat ~~ -.32*Depression
Persistence ~~ -.22*Anxiety
Persistence ~~ -.26*Depression
Anxiety ~~ .76*Depression
'
set.seed(240218)
dfSzy <- lavaan::simulateData(model = Szymanski_generating_model,
model.type = "sem",
meanstructure = T,
sample.nobs=646,
standardized=FALSE)
#used to retrieve column indices used in the rescaling script below
col_index <- as.data.frame(colnames(dfSzy))
#The code below loops through each column of the dataframe and assigns the scaling accordingly
#Rows 1 thru 6 are the Perceptions of LGBTQ Campus Climate Scale
#Rows 7 thru 15 are the Sexual Orientation-Based Campus Victimization Scale
#Rows 16 thru 20 are the College Satisfaction Scale
#Rows 21 thru 26 are the Institutional and Goals Commitment Scale
#Rows 27 thru 33 are the GAD7
#Rows 34 thru 42 are the PHQ9
for(i in 1:ncol(dfSzy)){
if(i >= 1 & i <= 6){
dfSzy[,i] <- scales::rescale(dfSzy[,i], c(1, 7))
}
if(i >= 7 & i <= 15){
dfSzy[,i] <- scales::rescale(dfSzy[,i], c(0, 3))
}
if(i >= 16 & i <= 20){
dfSzy[,i] <- scales::rescale(dfSzy[,i], c(1, 7))
}
if(i >= 21 & i <= 26){
dfSzy[,i] <- scales::rescale(dfSzy[,i], c(1, 5))
}
if(i >= 27 & i <= 33){
dfSzy[,i] <- scales::rescale(dfSzy[,i], c(0, 3))
}
if(i >= 34 & i <= 42){
dfSzy[,i] <- scales::rescale(dfSzy[,i], c(0, 3))
}
}
#rounding to integers so that the data resembles that which was collected
library(tidyverse)
dfSzy <- dfSzy %>% round(0)
#quick check of my work
#psych::describe(dfSzy)
#Reversing the supportive item on the Perceptions of LGBTQ Campus Climate Scale so that the exercises will be consistent with the format in which the data was collected
dfSzy <- dfSzy %>%
dplyr::mutate(supportiveNR = 8 - supportive)
#Reversing three items on the Institutional and Goals Commitments scale so that the exercises will be consistent with the format in which the data was collected
dfSzy <- dfSzy %>%
dplyr::mutate(not_graduateNR = 8 - not_graduate)%>%
dplyr::mutate(undecidedNR = 8 - undecided)%>%
dplyr::mutate(grades_unimportantNR = 8 - grades_unimportant)
dfSzy <- dplyr::select(dfSzy, -c(supportive, not_graduate, undecided, grades_unimportant))The optional script below will let you save the simulated data to your computing environment as either an .rds object (preserves any formatting you might do) or a.csv file (think “Excel lite”).
# to save the df as an .rds (think 'R object') file on your computer;
# it should save in the same file as the .rmd file you are working
# with saveRDS(dfSzy, 'SzyDF.rds') bring back the simulated dat from
# an .rds file dfSzy <- readRDS('SzyDF.rds')# write the simulated data as a .csv write.table(dfSzy,
# file='SzyDF.csv', sep=',', col.names=TRUE, row.names=FALSE) bring
# back the simulated dat from a .csv file dfSzy <-
# read.csv('SzyDF.csv', header = TRUE)If we look at the information about this particular scale, we recognize that the supportive item is scaled in the opposite direction of the rest of the items. That is, a higher score on supportive would indicate a positive perception of the campus climate for LGBTQ individuals, whereas higher scores on the remaining items indicate a more negative perception. Before moving forward, we must reverse score this item.
In this psychometrics example I have given my variables one-word names that represent each item. Many researchers (including myself) will often give variable names that are alpha numerical: LGBTQ1, LGBTQ2, LGBTQn. In the psychometric evaluations, the one-word names may be useful shortcuts as one begins to understand the inter-item relations.
In reverse-scoring the supportive item, I will rename it “unsupportive” as an indication of its reversed direction.
library(tidyverse)
dfSzy <- dfSzy %>%
dplyr::mutate(unsupportive = 8 - supportiveNR) #when reverse-coding, subtract the variable from one number higher than the scaling
# When unhashtagged, this code provides item-level descriptive
# statistics psych::describe(dfSzy)Next, I will create dfs that each contain the items of the total and subscales. These will be useful in the reliability estimates that follow.
Note that I am adding “T1” (time 1) to the end of the variable names. Later in the lesson when we evaluate test-retest reliability, we will simulate and add a “T2.
LGBTQT1 <- dplyr::select(dfSzy, cold, unresponsive, unsupportive, negative,
heterosexism, harassed)
ResponseT1 <- dplyr::select(dfSzy, cold, unresponsive, unsupportive)
StigmaT1 <- dplyr::select(dfSzy, negative, heterosexism, harassed)As we move into the lecture, allow me to provide a content advisory. Individuals who hold LGBTQIA+ identities are frequently the recipients of discrimination and harassment. If you are curious about why these items are considered to be stigmatizing or non-responsive, please do not ask a member of the LGBTQIA+ community to explain it to you; it is not their job to educate others on discrimination, harassment, and microaggressions. Rather, please read the article in its entirety. Additionally, resources such as The Trevor Project, GLSEN, and Campus Pride are credible sources of information for learning more.
5.4 A Parade of Reliability Coefficients
While I cluster the reliability coefficients into large groups, please understand that these are somewhat overlapping.
Table 1 in Revelle and Condon’s (2019a) article provides a summary of the type of reliability tested, the findings, and the function used in the psych package.
5.4.1 Reliability Options for a Single Administration
If reliability is defined as the correlation between a test and a test just like it, how do we estimate the reliability of a single test, given only one time (Revelle & Condon, 2019a)? It may help to keep in mind that reliability is the ratio of true score variance to test score variance (or 1 - the ratio of error variance). Thus, the goal is to estimate the amount of error variance in the test. In this case we can investigate:
- a correlation between two random parts of the test
- internal consistency
- the internal structure of the test
5.4.1.1 Split-half reliability
Split-half reliability is splitting a test into two random halves, correlating the two halves, and adjusting the correlation with the Spearman-Brown prophecy formula. Abundant formulaic detail in Revelle’s Chapter 7/Reliability (n.d.).
An important question to split-half is “How to split?” Revelle terms it a “combinatorially difficult problem.” There are 126 possible splits for a 10-item scale; 6,345 possible splits for a 16-item scale; and over 4.5 billion for a 36-item scale! The psych package’s splitHalf() function will try all possible splits for scales of up to 16 items, then sample 10,000 splits for scales longer than that.
split <- psych::splitHalf(LGBTQT1, raw = TRUE, brute = TRUE)
split #show the results of the analysisSplit half reliabilities
Call: psych::splitHalf(r = LGBTQT1, raw = TRUE, brute = TRUE)
Maximum split half reliability (lambda 4) = 0.73
Guttman lambda 6 = 0.68
Average split half reliability = 0.7
Guttman lambda 3 (alpha) = 0.7
Guttman lambda 2 = 0.71
Minimum split half reliability (beta) = 0.54
Average interitem r = 0.28 with median = 0.25
2.5% 50% 97.5%
Quantiles of split half reliability = 0.54 0.72 0.73hist(split$raw, breaks = 101, xlab = "Split-half reliability", main = "Split-half reliabilities of 6 LGBTQ items")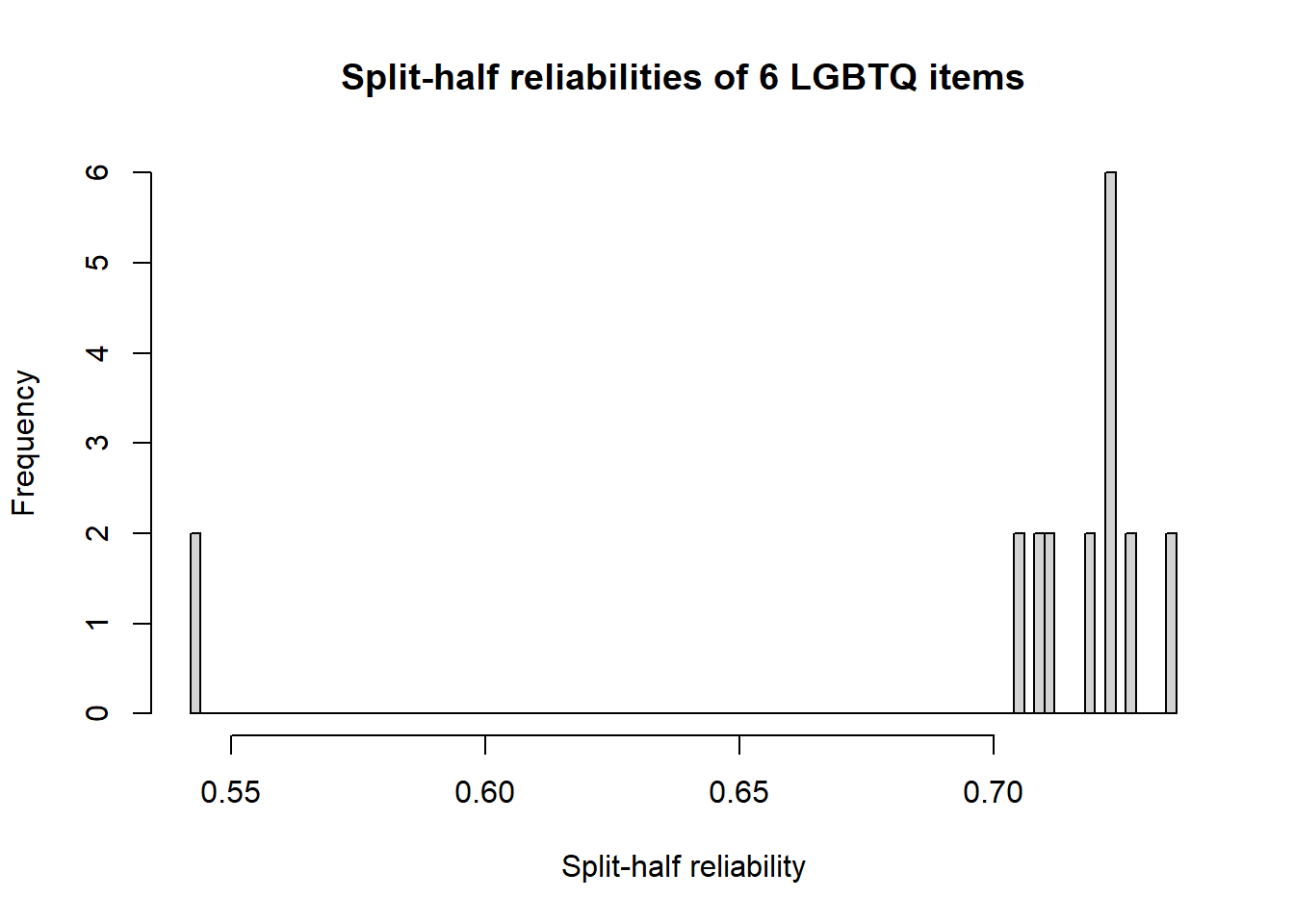
Results of the split-half can provide some indication of whether not the scale is unidimensional.
In this case, the maximum reliability coefficient is 0.73, the average 0.70, and the lowest is 0.54. Similarly, we can examine the quantiles: 0.54, 0.72, 0.73.
The split-half output also includes the classic Cronbach’s (1951) alpha coefficient (0.70; aka Guttman lambda 3) and average interitem correlations (0.25). The figure plots the frequencies of the reliability coefficient values.
While I did not find guidelines on what constitutes a “high enough lower bound” to establish homogeneity, Revelle suggested that a scale with 0.85, 0.80, and 0.65 had “strong evidence for a relatively homogeneous scale.” When the values were 0.81, 0.73, 0.42, Revelle indicated that there was “strong evidence for non-homogeneity” (Revelle & Condon, 2019b, p. 11). In making this declaration, Revelle was also looking at the strength of the inter-item correlation and for a rather tight, bell-shaped, distribution at the higher (> 0.73) end of the figure.
What happens when we examine the split-half estimates of the subscales? With only three items, there’s not much of a split and so the associated histogram will not be helpful.
splitRx <- psych::splitHalf(ResponseT1, raw = TRUE, brute = TRUE)
splitRx #show the results of the analysisSplit half reliabilities
Call: psych::splitHalf(r = ResponseT1, raw = TRUE, brute = TRUE)
Maximum split half reliability (lambda 4) = 0.62
Guttman lambda 6 = 0.57
Average split half reliability = 0.59
Guttman lambda 3 (alpha) = 0.66
Guttman lambda 2 = 0.66
Minimum split half reliability (beta) = 0.56
Average interitem r = 0.39 with median = 0.4
2.5% 50% 97.5%
Quantiles of split half reliability = 0.57 0.58 0.62hist(splitRx$raw, breaks = 101, xlab = "Split-half reliability", main = "Split-half reliabilities of 3 items of the College Response subscale")
The alpha is 0.66. The range of splits for max, ave, and low are 0.62, 0.59, and 0.55 and the quantiles are 0.57, 0.58, 0.62. The inter-item correlations have an average of 0.40.
Let’s look at the split-half reliability coefficients for the Stigma subscale.
splitSt <- psych::splitHalf(StigmaT1, raw = TRUE, brute = TRUE)
splitSt #show the results of the analysisSplit half reliabilities
Call: psych::splitHalf(r = StigmaT1, raw = TRUE, brute = TRUE)
Maximum split half reliability (lambda 4) = 0.56
Guttman lambda 6 = 0.53
Average split half reliability = 0.56
Guttman lambda 3 (alpha) = 0.63
Guttman lambda 2 = 0.63
Minimum split half reliability (beta) = 0.55
Average interitem r = 0.36 with median = 0.36
2.5% 50% 97.5%
Quantiles of split half reliability = 0.55 0.56 0.56hist(splitRx$raw, breaks = 101, xlab = "Split-half reliability", main = "Split-half reliabilities of 3 items of the Stigma subscale") The alpha of this subscale is lower than the total scale score \((\alpha = 0.60\)). The maximum, average, and minimum split-half reliabilities were 0.56, 0.56, and 0.55; quantiles were at 0.55, 0.56, and 0.56. The average interitem correlation was 0.36.
The alpha of this subscale is lower than the total scale score \((\alpha = 0.60\)). The maximum, average, and minimum split-half reliabilities were 0.56, 0.56, and 0.55; quantiles were at 0.55, 0.56, and 0.56. The average interitem correlation was 0.36.
Because the alpha coefficient can be defined as the “average of all possible split-half coefficients” for the groups tested, it is common for researchers to not provide split-half results in their papers – this is true for our research vignette. I continue to teach the split-half because it can be a stepping stone in the conceptualization of internal consistency as an estimate of reliability.
5.4.1.2 Alpha coefficients
The most common methods to assess internal consistency are the KR20 (for dichotomous items) and \(\alpha\) (for Likert scaling); alpha has an alias, \(\lambda _{3}\) (i.e., the Guttman lambda 3).
Alpha and the Guttman 3 (used for scales with Likert-type scaling) may be thought of as:
- a function of the number of items and the average correlation between the items
- the correlation of a test with a non-existent test just like it
- average of all possible split-half coefficients for the groups tested
Although the psych package has an incredible and thorough alpha() function, Revelle is not a fan of alpha. In fact, his alpha function reports a 95% CI around alpha as well as bootstrapped alpha results.
Let’s grab alpha coefficients for our total and subscales.
Reliability analysis
Call: psych::alpha(x = LGBTQT1)
raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
0.7 0.7 0.68 0.28 2.4 0.018 4 0.63 0.25
95% confidence boundaries
lower alpha upper
Feldt 0.66 0.7 0.74
Duhachek 0.66 0.7 0.74
Reliability if an item is dropped:
raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
cold 0.64 0.64 0.61 0.27 1.8 0.022 0.0066 0.22
unresponsive 0.66 0.66 0.63 0.28 2.0 0.021 0.0073 0.25
unsupportive 0.67 0.67 0.63 0.29 2.0 0.021 0.0058 0.25
negative 0.66 0.66 0.63 0.28 2.0 0.021 0.0084 0.25
heterosexism 0.66 0.66 0.63 0.28 2.0 0.021 0.0087 0.25
harassed 0.67 0.67 0.64 0.29 2.0 0.021 0.0078 0.25
Item statistics
n raw.r std.r r.cor r.drop mean sd
cold 646 0.68 0.68 0.59 0.49 4.1 1.03
unresponsive 646 0.63 0.63 0.51 0.43 4.3 0.99
unsupportive 646 0.62 0.62 0.51 0.42 3.7 0.98
negative 646 0.64 0.63 0.51 0.42 4.0 1.04
heterosexism 646 0.61 0.63 0.51 0.43 4.0 0.90
harassed 646 0.63 0.61 0.49 0.41 3.9 1.07
Non missing response frequency for each item
1 2 3 4 5 6 7 miss
cold 0.00 0.04 0.22 0.40 0.23 0.09 0.00 0
unresponsive 0.00 0.03 0.17 0.37 0.33 0.09 0.01 0
unsupportive 0.01 0.07 0.35 0.37 0.17 0.02 0.01 0
negative 0.01 0.07 0.23 0.39 0.24 0.05 0.00 0
heterosexism 0.00 0.03 0.24 0.43 0.26 0.03 0.00 0
harassed 0.01 0.07 0.27 0.37 0.22 0.05 0.01 0The second screen of output shows the information we are interested in:
- raw_alpha, .70 is based on the covariances
- std.apha, .70 is based on correlations
- average_r, .28 is the average inter-item correlation (i.e., all possible pairwise combinations of items)
Reliability analysis
Call: psych::alpha(x = ResponseT1)
raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
0.66 0.66 0.57 0.39 1.9 0.023 4 0.77 0.4
95% confidence boundaries
lower alpha upper
Feldt 0.61 0.66 0.70
Duhachek 0.62 0.66 0.71
Reliability if an item is dropped:
raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
cold 0.52 0.52 0.35 0.35 1.1 0.038 NA 0.35
unresponsive 0.60 0.60 0.42 0.42 1.5 0.032 NA 0.42
unsupportive 0.58 0.58 0.40 0.40 1.4 0.033 NA 0.40
Item statistics
n raw.r std.r r.cor r.drop mean sd
cold 646 0.80 0.79 0.62 0.50 4.1 1.03
unresponsive 646 0.76 0.76 0.55 0.45 4.3 0.99
unsupportive 646 0.76 0.77 0.57 0.46 3.7 0.98
Non missing response frequency for each item
1 2 3 4 5 6 7 miss
cold 0.00 0.04 0.22 0.40 0.23 0.09 0.00 0
unresponsive 0.00 0.03 0.17 0.37 0.33 0.09 0.01 0
unsupportive 0.01 0.07 0.35 0.37 0.17 0.02 0.01 0In the case of the College Response subscale:
- raw_alpha, .66 is based on the covariances
- std.apha, .66 is based on correlations
- average_r, .39 is the average interitem correlation
Reliability analysis
Call: psych::alpha(x = StigmaT1)
raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
0.62 0.63 0.53 0.36 1.7 0.025 4 0.76 0.36
95% confidence boundaries
lower alpha upper
Feldt 0.57 0.62 0.67
Duhachek 0.57 0.62 0.67
Reliability if an item is dropped:
raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
negative 0.52 0.52 0.35 0.35 1.1 0.038 NA 0.35
heterosexism 0.53 0.53 0.36 0.36 1.1 0.037 NA 0.36
harassed 0.53 0.54 0.37 0.37 1.2 0.036 NA 0.37
Item statistics
n raw.r std.r r.cor r.drop mean sd
negative 646 0.77 0.76 0.56 0.44 4.0 1.0
heterosexism 646 0.73 0.76 0.55 0.44 4.0 0.9
harassed 646 0.77 0.75 0.54 0.43 3.9 1.1
Non missing response frequency for each item
1 2 3 4 5 6 7 miss
negative 0.01 0.07 0.23 0.39 0.24 0.05 0.00 0
heterosexism 0.00 0.03 0.24 0.43 0.26 0.03 0.00 0
harassed 0.01 0.07 0.27 0.37 0.22 0.05 0.01 0In the case of the Stigma subscale:
- raw_alpha, .62 is based on the covariances
- std.apha, .63 is based on correlations
- average_r, .36 is the average interitem correlation
The documentation for this package is incredible. Scrolling down through the description of the alpha() function provides a description of these different statistics.
Especially useful are item-level statistics:
- r.drop is the corrected item-total correlation (in the next lesson) for this item against the remaining items in the scale
- mean and sd are the mean and standard deviation of each item across all individuals.
The popularity of alpha emerged when tools available for calculation were less sophisticated; since then, we have learned that alpha can be misleading:
- Alpha inflates, somewhat artificially, even when inter-item correlations are low.
- A 14-item scale will have an alpha of at least .70, even if it has two orthogonal (i.e., unrelated) scales (Cortina, 1993).
- Alpha assumes a unidimensional factor structure.
- The same alpha can be obtained for dramatically different underlying factor structures (see graphs in Revelle’s Chapter 7).
The proper use of alpha requires the following:
- Tau equivalence, that is, equal covariances with the latent score represented by the test.
- Unidimensionality, equal factor loadings on the single factor of the test.
When either of these is violated, alpha underestimates reliability and overestimates the fraction of test variance that is associated with the general variance in the test.
Alpha and the split half are internal consistency estimates. Moving to model-based techniques allows us to take into consideration the factor structure of the scale. In the original article (Szymanski & Bissonette, 2020), results were as follows:
5.4.1.3 Omega
Assessing reliability with omega (\(\omega\)) statistics falls into a larger realm of composite reliability where reliability is assessed from a ratio of the variability explained by the items compared with the total variance of the entire scale (McNeish, 2018). Members of the omega family of reliability estimates come from factor exploratory (i.e., EFA) and confirmatory (i.e., CFA; structural equation modeling [SEM]) factor analytic approaches. This lesson precedes the lessons on CFA and SEM. Therefore, my explanations and demonstrations will be somewhat brief. I intend to revisit omega output in the CFA and SEM lessons and encourage you to review this section now, then return to this section again after learning more about CFA and SEM.
In the context of psychometrics, it may be useful (albeit an oversimplification) to think of factors as scales/subscales where g refers to the amount of variance in the general factor (or total scale score) and subscales to be items that have something in common that is separate from what is g.
Model-based estimates examine the correlations or covariances of the items and decompose the test variance into that which is:
- common to all items (g, a general factor),
- specific to some items (f, orthogonal group factors), and
- unique to each item (confounding s specific, and e error variance)
\(\omega\) is something of a shapeshifter. In the psych package:
- \(\omega_{t}\) represents the total reliability of the test (\(\omega_{t}\))
- In the psych package, this is calculated from a bifactor model where there is one general g factor (i.e., each item loads on the single general factor), one or more group factors (f), and item-specific factors.
- \(\omega_{h}\) extracts a higher-order factor from the correlation matrix of lower-level factors, then applies the Schmid and Leiman (1957) transformation to find the general loadings on the original items. Stated another way, it is a measure of the general factor saturation (g; the amount of variance attributable to one common factor). The subscript “h” acknowledges the hierarchical nature of the approach.
- the \(\omega_{h}\) approach is exploratory and defined if there are three or more group factors (with only two group factors, the default is to assume they are equally important, hence the factor loadings of those subscales will be equal)
- Najera Catalan (Najera Catalan, 2019) suggests that \(\omega_{h}\) is the best measure of reliability when dealing with multiple dimensions.
- \(\omega_{g}\) is an estimate that uses a bifactor solution via the SEM package lavaan and tends to be a larger (because it forces all the cross loadings of lower-level factors to be 0)
- the \(\omega_{g}\) is confirmatory, requiring the specification of which variables load on each group factor
Two commands in psych get us the results:
- omega() reports only the EFA solution
- omegaSem() reports both EFA and CFA solutions
- We will use the omegaSem() function
Note that in our specification, we indicate there are two factors. We do not tell it what items belong to what factors (think, subscales). One test will be to see if the items align with their respective factors.
Loading required namespace: GPArotation
Three factors are required for identification -- general factor loadings set to be equal.
Proceed with caution.
Think about redoing the analysis with alternative values of the 'option' setting.Warning in lav_model_vcov(lavmodel = lavmodel, lavsamplestats = lavsamplestats, : lavaan WARNING:
Could not compute standard errors! The information matrix could
not be inverted. This may be a symptom that the model is not
identified.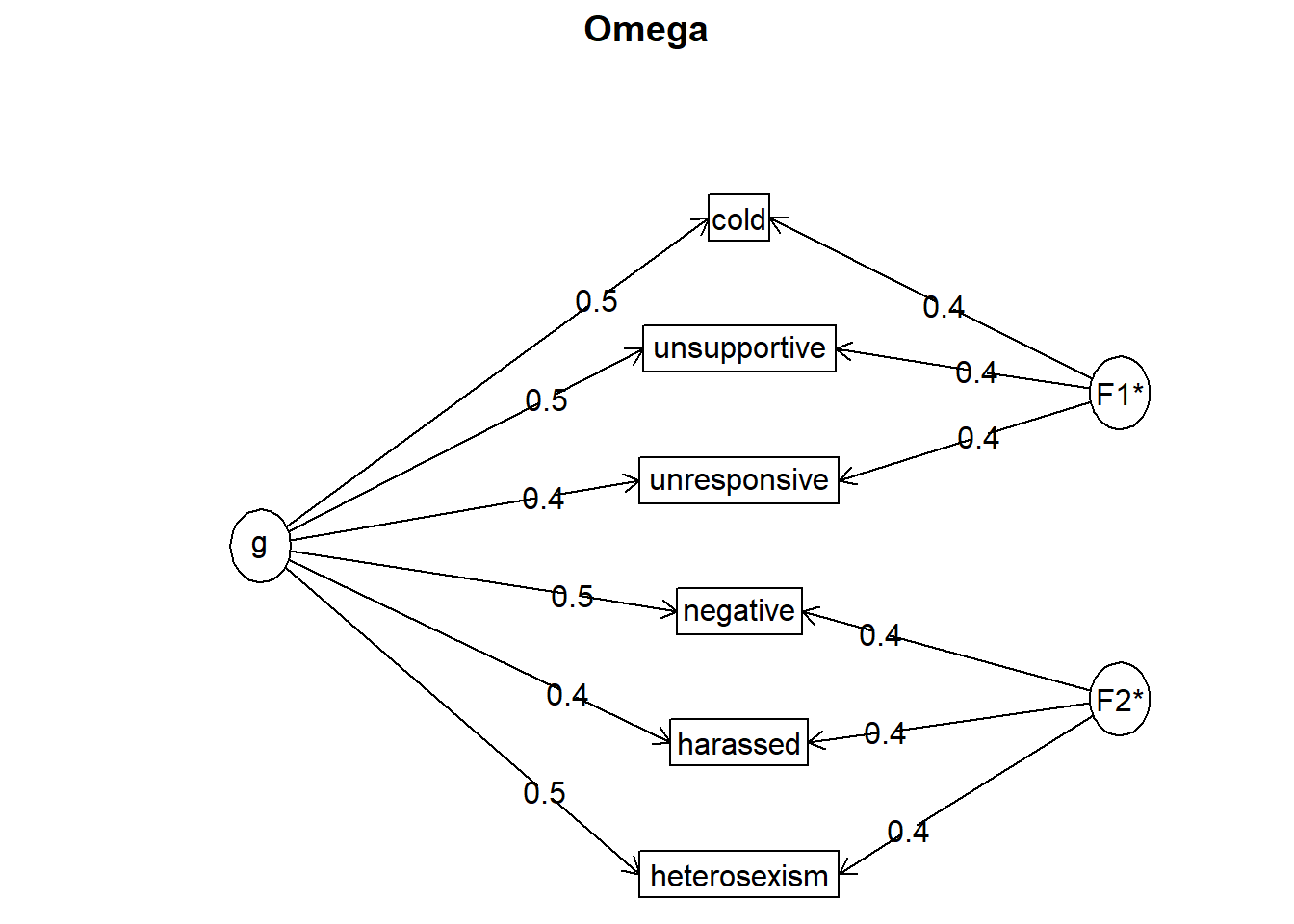
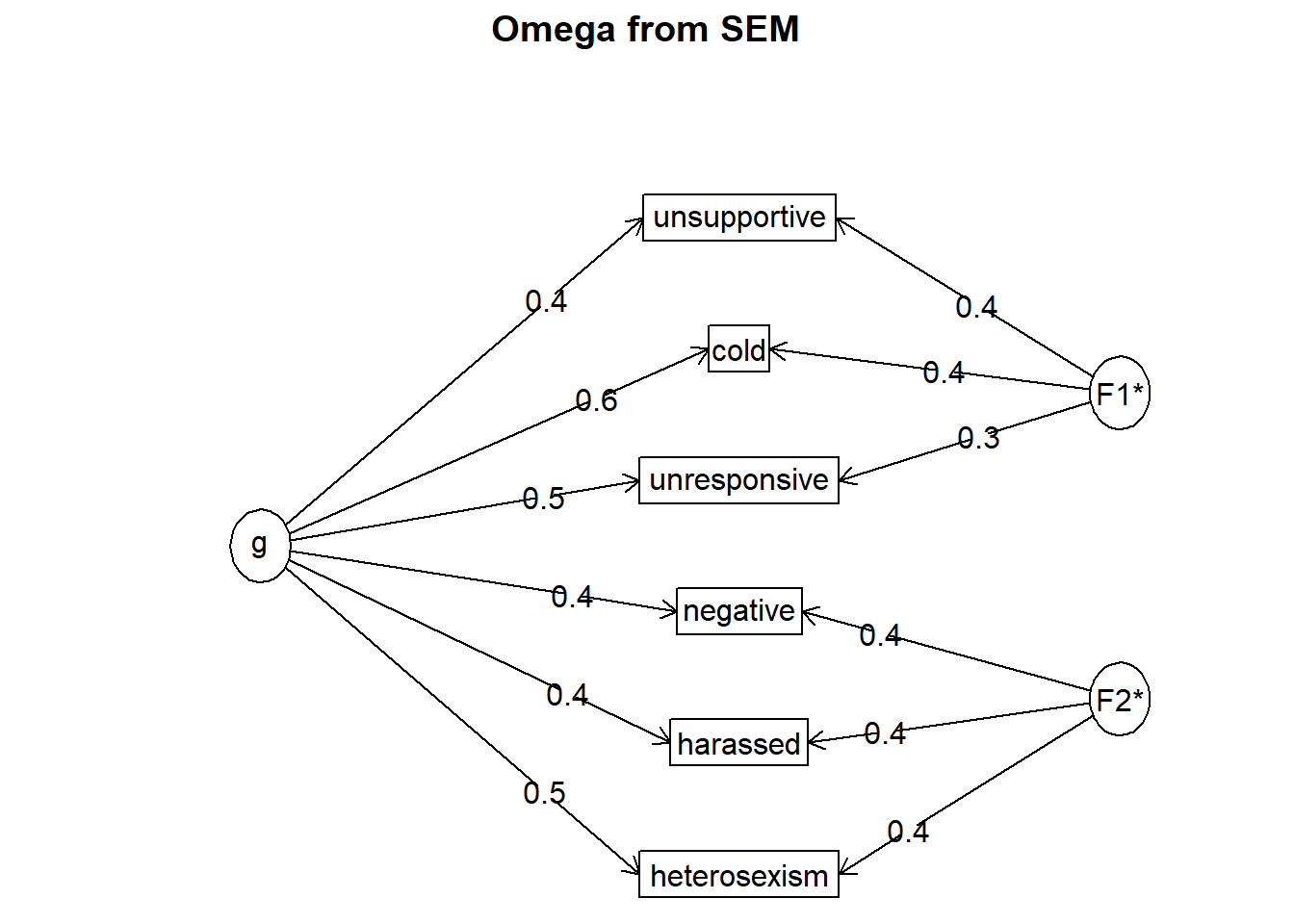
Call: psych::omegaSem(m = LGBTQT1, nfactors = 2)
Omega
Call: omegah(m = m, nfactors = nfactors, fm = fm, key = key, flip = flip,
digits = digits, title = title, sl = sl, labels = labels,
plot = plot, n.obs = n.obs, rotate = rotate, Phi = Phi, option = option,
covar = covar)
Alpha: 0.7
G.6: 0.68
Omega Hierarchical: 0.54
Omega H asymptotic: 0.73
Omega Total 0.74
Schmid Leiman Factor loadings greater than 0.2
g F1* F2* h2 u2 p2
cold 0.53 0.45 0.49 0.51 0.59
unresponsive 0.45 0.37 0.34 0.66 0.60
unsupportive 0.45 0.41 0.37 0.63 0.55
negative 0.46 0.40 0.37 0.63 0.58
heterosexism 0.46 0.39 0.36 0.64 0.59
harassed 0.44 0.39 0.35 0.65 0.56
With Sums of squares of:
g F1* F2*
1.31 0.51 0.46
general/max 2.59 max/min = 1.1
mean percent general = 0.58 with sd = 0.02 and cv of 0.03
Explained Common Variance of the general factor = 0.58
The degrees of freedom are 4 and the fit is 0
The number of observations was 646 with Chi Square = 2.59 with prob < 0.63
The root mean square of the residuals is 0.01
The df corrected root mean square of the residuals is 0.02
RMSEA index = 0 and the 10 % confidence intervals are 0 0.049
BIC = -23.3
Compare this with the adequacy of just a general factor and no group factors
The degrees of freedom for just the general factor are 9 and the fit is 0.18
The number of observations was 646 with Chi Square = 115.31 with prob < 0.000000000000000000012
The root mean square of the residuals is 0.1
The df corrected root mean square of the residuals is 0.13
RMSEA index = 0.135 and the 10 % confidence intervals are 0.114 0.158
BIC = 57.08
Measures of factor score adequacy
g F1* F2*
Correlation of scores with factors 0.74 0.57 0.56
Multiple R square of scores with factors 0.54 0.33 0.31
Minimum correlation of factor score estimates 0.09 -0.34 -0.38
Total, General and Subset omega for each subset
g F1* F2*
Omega total for total scores and subscales 0.74 0.66 0.63
Omega general for total scores and subscales 0.54 0.38 0.36
Omega group for total scores and subscales 0.20 0.28 0.27
The following analyses were done using the lavaan package
Omega Hierarchical from a confirmatory model using sem = 0.54
Omega Total from a confirmatory model using sem = 0.74
With loadings of
g F1* F2* h2 u2 p2
cold 0.56 0.42 0.49 0.51 0.64
unresponsive 0.47 0.33 0.34 0.66 0.65
unsupportive 0.44 0.42 0.38 0.62 0.51
negative 0.45 0.42 0.37 0.63 0.55
heterosexism 0.46 0.39 0.36 0.64 0.59
harassed 0.43 0.40 0.34 0.66 0.54
With sum of squared loadings of:
g F1* F2*
1.32 0.46 0.49
The degrees of freedom of the confirmatory model are 3 and the fit is 2.658827 with p = 0.4472696
general/max 2.71 max/min = 1.05
mean percent general = 0.58 with sd = 0.06 and cv of 0.1
Explained Common Variance of the general factor = 0.58
Measures of factor score adequacy
g F1* F2*
Correlation of scores with factors 0.74 0.55 0.58
Multiple R square of scores with factors 0.55 0.31 0.33
Minimum correlation of factor score estimates 0.10 -0.39 -0.34
Total, General and Subset omega for each subset
g F1* F2*
Omega total for total scores and subscales 0.74 0.66 0.63
Omega general for total scores and subscales 0.54 0.41 0.34
Omega group for total scores and subscales 0.20 0.26 0.28
To get the standard sem fit statistics, ask for summary on the fitted objectThere is a ton of output! How do we make sense of it?
First, our items aligned perfectly with their respective factors (subscales). That is, it would be problematic if the items switched factors.
Second, we can interpret our results. Like alpha, the omegas range from 0 to 1, where values closer to 1 represent good reliability (Najera Catalan, 2019). For unidimensional measures, \(\omega_{t}\) values above 0.80 indicate satisfactory reliability. For multidimensional measures with well-defined dimensions, we strive for \(\omega_{h}\) values above 0.65 (and \(\omega_{t}\) > 0.8). These recommendations are based on a Monte Carlo study that examined a host of reliability indicators and how their values corresponded with accurate predictions of poverty status. With this in mind, let’s examine the output related to our simulated research vignette.
Let’s start with the output in the lower portion where the values are “from a confirmatory model using sem.”
Omega is a reliability estimate for factor analysis that represents the proportion of variance in the LGBTQ scale attributable to common variance rather than error. The omega for the total reliability of the test (\(\omega_{t}\); which included the general factors and the subscale factors) was .74, meaning that 74% of the variance in the total scale is due to the factors and 26% (100% - 74%) is attributable to error.
Omega hierarchical (\(\omega_{h}\)) estimates are the proportion of variance in the LGBTQ score attributable to the general factor, which in effect treats the subscales as error. \(\omega_{h}\) for the the LGBTQ total scale was .54. A quick calculation with \(\omega_{h}\) (.54) and \(\omega_{t}\) (.74; .54/.74 = .72) lets us know that that 73% of the reliable variance in the LGBTQ total scale is attributable to the general factor.
[1] 0.7297297Amongst the output is the Cronbach’s alpha coefficient (.70). Szymanski and Bissonette (2020) did not report omega results; this may be because there were only two subfactors and/or they did not feel like a bifactor analysis would be appropriate. You might notice the lavaan warning indicating that three factors are needed in order to identify the CFA model. There is a longer explanation about factor identification. Stay tuned for CFA models.
5.4.1.4 Some summary statements about reliability from single administrations
- With the exception of the worst split-half reliability and \(\omega_{g}\) or \(\omega_{h}\), all of the reliability estimates are functions of test length and will tend asymptotically towards 1 as the number of items increases.
- The omega output provides a great deal more information about reliability than a simple alpha.
- Figure 7.5 in Revelle’s chapter shows four different structural representations of measures that have equal alphas (all .72)
- \(\omega_{(h)}\), \(\beta\), and the worst split-half reliability are estimates of the amount of general factor variance in the test scores
- In the case of low general factor saturation, the EFA based \(\omega_{(h)}\) is positively biased, so the CFA-based estimate, \(\omega_{(g)}\), should be used.
- \(\omega_{(t)}\) is the model-based estimate of the greatest lower bound of the total reliability of the test; so is the best split-half reliability.
Revelle and Condon’s (2019b) recommendations to researchers:
- Report at least two coefficients (e.g., \(\omega_{(h)}\) and \(\omega_{(t)}\)) and discuss why each is appropriate for the inference that is being made.
- Report more than “just alpha” unless you can demonstrate that the measure is tau equivalent and unidimensional.
5.4.2 Reliability Options for Two or more Administrations
5.4.2.1 Test-retest of total scores
The purpose of test-retest reliability is to understand the stability of the measure over time. With two time points, T1 and T2, the test-retest correlation is an unknown mixture of trait, state, and specific variance, and is a function of the length of time between two measures.
- With two time points we cannot distinguish between trait and state effects, that said
- we would expect a high degree of stability if the retest were (relatively) immediate
- With three time points we can leverage some SEM tools to distinguish between trait and state components
- A large test-retest correlation over a long period of time indicates temporal stability. Temporal stability is:
- expected if we are assessing something trait like (e.g., cognitive ability, personality trait)
- not expected if we are assessing something state like (e.g., emotional state, mood)
- not expected if there was an intervention (or condition) and the T1 and T2 administrations are part of a pre- and post-test design.
There are some methodological concerns about test-retest reliability. For example, owing to memory and learning effects, the average response time to a second administration of identical items takes about 80% the time compared to the first administration.
Szymanski and Bissonette (2020) did not assess retest reliability. We can, though, imagine how this might work. Let’s imagine that both waves were taken in the same academic term, approximately two weeks apart.
With both sets of data we need to create scores for the total scale score and the two subscales. We would also need to join the two datasets into a single dataframe.
To demonstrate the retest reliability, I simulated a new dataset with total and subscale scores for our variables for Time 1 and Time 2. This next script is simply that simulation (i.e., you can skip over it). If this were your data, you would have item-level data and need to calculate total and subscale scores (as we did above).
SimCor_mu <- c(3.13, 2.68, 3.58, 3.16, 2.66, 2.76)
SimCor_sd <- c(0.82, 1.04, 1.26, 0.83, 1.05, 0.99)
simCor <- matrix(c(1, 0.64, 0.77, 0.44, 0.33, 0.29, 0.64, 1, 0.53, 0.35,
0.46, 0.34, 0.77, 0.53, 1, 0.27, 0.4, 0.47, 0.44, 0.35, 0.27, 1, 0.63,
0.62, 0.33, 0.46, 0.4, 0.63, 1, 0.57, 0.29, 0.34, 0.47, 0.62, 0.57,
1), ncol = 6)
scovMat <- SimCor_sd %*% t(SimCor_sd) * simCor
set.seed(210829)
retest_df <- MASS::mvrnorm(n = 646, mu = SimCor_mu, Sigma = scovMat, empirical = TRUE)
colnames(retest_df) <- c("TotalT1", "ResponseT1", "StigmaT1", "TotalT2",
"ResponseT2", "StigmaT2")
retest_df <- as.data.frame(retest_df) #converts to a df so we can use in R
library(dplyr)
retest_df <- retest_df %>%
dplyr::mutate(ID = row_number()) #add ID to each row
retest_df <- retest_df %>%
dplyr::select(ID, everything()) #moving the ID number to the first column; requiresExaming our df, we can see the ID variable and the three sets of scores for each wave of analysis. Now we simply ask for their correlations. There are a number of ways to do this – the apaTables package can do the calculations and pop it into a manuscript-ready table.
We won’t want the ID variable to be in the table.
apaTables::apa.cor.table(data = retest_df2, landscape = TRUE, table.number = 1,
filename = "Table_1_Retest.doc")
Table 1
Means, standard deviations, and correlations with confidence intervals
Variable M SD 1 2 3 4
1. TotalT1 3.13 0.82
2. ResponseT1 2.68 1.04 .64**
[.59, .68]
3. StigmaT1 3.58 1.26 .77** .53**
[.74, .80] [.47, .58]
4. TotalT2 3.16 0.83 .44** .35** .27**
[.38, .50] [.28, .42] [.20, .34]
5. ResponseT2 2.66 1.05 .33** .46** .40** .63**
[.26, .40] [.40, .52] [.33, .46] [.58, .67]
6. StigmaT2 2.76 0.99 .29** .34** .47** .62**
[.22, .36] [.27, .41] [.41, .53] [.57, .67]
5
.57**
[.52, .62]
Note. M and SD are used to represent mean and standard deviation, respectively.
Values in square brackets indicate the 95% confidence interval.
The confidence interval is a plausible range of population correlations
that could have caused the sample correlation (Cumming, 2014).
* indicates p < .05. ** indicates p < .01.
As expected in this simulation,
- the strongest correlations are within each scale at their respective time, that is:
- the T1 variables correlate with each other;
- the T2 variables correlate with each other.
- the next strongest correlations are with the same scale/subscale configuration across time, for example
- TotalT1 with TotalT2 (r = .44, p < 0.01)
- ResponseT1 with ResponseT2 (r = .46, p < 0.01)
- StigmaT1 with StigmaT2 (r = .47, p < 0.01)
- the lowest correlations are different scales at T1 and T2
- ResponseT1 with StigmaT2 (r = .29)
The range of retest correlations (e.g., .44 to .47 with p < 0.01) are sufficient to be confident in test-retest reliability.
5.4.2.2 Test-retest recap
Here are some summary notions for retest reliability:
- Increases in the time interval will lower the reliability coefficient.
- An experimental intervention that is designed to impact the retest assessment will lower the reliability coefficient.
- State measures will have lower retest coefficients than trait measures.
- The three phenomena above all interact with each other.
Revelle and Condon’s (2019b, 2019a) materials elaborate on this further. Their Table 1 is especially helpful. In addition to the myriad of vignettes used to illustrate issues with state, trait, items, whole scale, and so forth, there are demonstrations for duplicated items, assessing for consistency, and parallel/alternate forms.
If you are asking, “Hey, is parallel/alternate forms really a variant of test retest?” Great question! In fact, split-half could be seen as test-retest! Once you get in the weeds, the distinctions become less clear.
5.4.3 Interrater Reliability
5.4.3.1 Cohen’s kappa
Cohen’s kappa coefficient is used to calculate proportions of agreement corrected for chance. This type of analysis occurs in research designs where there is some kind of (usually) categorical designation of a response. I don’t have an outside research vignette for this. In the past, I was involved in research where members of the research team coded counselor utterances according to Hill’s helping skills system designed by Clara Hill (Hill, 2020). In the helping skills system, 15 different helping skills are divided into three larger groups that generally reflect the counseling trajectory: exploration, insight, action. One of our analyses coded counselor utterances into these three categories. Let’s look at a fabricated (not based on any real data) simulation where four raters each evaluated 12 counselor utterances (that represent the arch of a nonsensically speedy counseling session).
Rater1 <- c("exploration", "exploration", "exploration", "exploration",
"exploration", "exploration", "insight", "insight", "action", "action",
"action", "action")
Rater2 <- c("exploration", "exploration", "exploration", "insight", "exploration",
"insight", "exploration", "exploration", "exploration", "action", "exploration",
"action")
Rater3 <- c("exploration", "insight", "exploration", "exploration", "exploration",
"exploration", "exploration", "insight", "insight", "insight", "action",
"action")
Rater4 <- c("exploration", "exploration", "exploration", "exploration",
"exploration", "exploration", "exploration", "exploration", "exploration",
"action", "action", "action")
ratings <- data.frame(Rater1, Rater2, Rater3, Rater4)Historically, kappa could only be calculated for 2 raters at a time. Presently, though, it appears there can be any number of raters and the average agreement is reported.
Let’s take a look at the data, then run the analysis, and interpret the results.
Cohen Kappa (below the diagonal) and Weighted Kappa (above the diagonal)
For confidence intervals and detail print with all=TRUE
Rater1 Rater2 Rater3 Rater4
Rater1 1.00 0.40 0.21 0.62
Rater2 0.14 1.00 0.00 0.57
Rater3 0.48 0.00 1.00 0.30
Rater4 0.54 0.45 0.43 1.00
Average Cohen kappa for all raters 0.34
Average weighted kappa for all raters 0.35Kappa can range from -1.00 to 1.00.
- K = .00 indicates that the observed agreement is exactly equal to the agreement that could be observed by chance.
- Negative kappa indicates that observed kappa is less than the expected chance agreement.
- K = 1.00 equals perfect agreement between judges.
There are commonly understood concerns about using kappa:
- Research teams typically set an expected standard (e.g., .85) and train raters until kappa is achieved.
- In lengthy projects, rating agreement is rechecked periodically; if necessary there is retraining.
- Obtaining an acceptable kappa becomes difficult as the number of categories increases.
- An example is Hill’s Helping Skills System when all 15 categories; we chose to use the three categories (into which the 15 categories are subsumed).
- It is also difficult to obtain an adequate kappa when infrequent categories (e.g., “insight”) exist.
Our kappa of .35 indicates that this rating team has a 35% chance of agreement, corrected for by chance. This is substantially below the standard. Let’s imagine that the team spends time with their dictionaries, examines common errors, and makes some decision rules.
Here’s the resimulation of the “improved” agreement.
Rater1b <- c("exploration", "exploration", "exploration", "exploration",
"exploration", "exploration", "insight", "insight", "insight", "action",
"action", "action")
Rater2b <- c("exploration", "exploration", "exploration", "exploration",
"exploration", "insight", "insight", "insight", "exploration", "action",
"action", "action")
Rater3b <- c("exploration", "exploration", "exploration", "exploration",
"exploration", "exploration", "exploration", "insight", "insight",
"insight", "action", "action")
Rater4b <- c("exploration", "exploration", "exploration", "exploration",
"exploration", "exploration", "exploration", "exploration", "insight",
"action", "action", "action")
after_training <- data.frame(Rater1b, Rater2b, Rater3b, Rater4b)Now run it again.
Warning in cohen.kappa1(x1, w = w, n.obs = n.obs, alpha = alpha, levels =
levels): upper or lower confidence interval exceed abs(1) and set to +/- 1.
Warning in cohen.kappa1(x1, w = w, n.obs = n.obs, alpha = alpha, levels =
levels): upper or lower confidence interval exceed abs(1) and set to +/- 1.
Warning in cohen.kappa1(x1, w = w, n.obs = n.obs, alpha = alpha, levels =
levels): upper or lower confidence interval exceed abs(1) and set to +/- 1.
Warning in cohen.kappa1(x1, w = w, n.obs = n.obs, alpha = alpha, levels =
levels): upper or lower confidence interval exceed abs(1) and set to +/- 1.
Cohen Kappa (below the diagonal) and Weighted Kappa (above the diagonal)
For confidence intervals and detail print with all=TRUE
Rater1b Rater2b Rater3b Rater4b
Rater1b 1.00 0.83 0.55 0.80
Rater2b 0.73 1.00 0.36 0.60
Rater3b 0.72 0.45 1.00 0.46
Rater4b 0.71 0.43 0.70 1.00
Average Cohen kappa for all raters 0.62
Average weighted kappa for all raters 0.6We observe improved scores, but this team needs more training if we aspire to a kappa of 0.85!
5.4.3.2 Intraclass correlation (ICC)
Another option for interrater reliability is the intraclass correlation (ICC). This is the same ICC we use in multilevel modeling! The ICC is used when we have numerical ratings.
In our fabricated vignette below, five raters are evaluating the campus climate for LGBTQIA+ individuals for 10 units/departments on a college campus. Using the ICC can help us determine the degree of leniency and variability within judges.
Below is a simulation of the data (you can ignore this)…
Rater1 <- c(1, 1, 1, 4, 2, 3, 1, 3, 3, 5)
Rater2 <- c(1, 1, 2, 1, 4, 4, 4, 4, 5, 5)
Rater3 <- c(3, 3, 3, 2, 3, 3, 6, 4, 4, 5)
Rater4 <- c(3, 5, 4, 2, 3, 6, 6, 6, 5, 5)
Rater5 <- c(2, 3, 3, 3, 4, 4, 4, 4, 5, 5)
ICC_df <- data.frame(Rater1, Rater2, Rater3, Rater4, Rater5)#If the code below will not run remove the hashtags from the two lines of code below to install the Matrix package and then the lme4 package from its source
#tools::package_dependencies("Matrix", which = "LinkingTo", reverse = TRUE)[[1L]]
#install.packages("lme4", type = "source")We can use the psych::ICC function to obtain the ICC values.
# psych::ICC(ICC_df [1:10,1:5], lmer = TRUE) #find the ICCs for the
# 10 campus units and 5 judges
psych::ICC(ICC_df, missing = TRUE, alpha = 0.05, lmer = TRUE, check.keys = FALSE)Call: psych::ICC(x = ICC_df, missing = TRUE, alpha = 0.05, lmer = TRUE,
check.keys = FALSE)
Intraclass correlation coefficients
type ICC F df1 df2 p lower bound upper bound
Single_raters_absolute ICC1 0.34 3.5 9 40 0.00259 0.082 0.70
Single_random_raters ICC2 0.37 5.4 9 36 0.00011 0.118 0.71
Single_fixed_raters ICC3 0.47 5.4 9 36 0.00011 0.188 0.78
Average_raters_absolute ICC1k 0.72 3.5 9 40 0.00259 0.308 0.92
Average_random_raters ICC2k 0.74 5.4 9 36 0.00011 0.400 0.92
Average_fixed_raters ICC3k 0.81 5.4 9 36 0.00011 0.537 0.95
Number of subjects = 10 Number of Judges = 5
See the help file for a discussion of the other 4 McGraw and Wong estimates,In the output, reliability for a single judge \(ICC_1\) is the ratio of person variance to total variance. Reliability for multiple judges \(ICC_1k\) adjusts the residual variance by the number of judges.
The ICC function reports six reliability coefficients: 3 for the case of single judges and 3 for the case of multiple judges. It also reports the results in terms of a traditional ANOVA as well as a mixed effects linear model. Additionally, confidence intervals are reported.
Like most correlation coefficients, the ICC ranges from 0 to 1.
- An ICC close to 1 indicates high similarity between values from the same group.
- An ICC close to zero means that values from the same group are not similar.
5.5 What do we do with these coefficients?
5.5.1 Corrections for attenuation
Circa 1904, Spearman created the reliability coefficient out of a need to adjust observed correlations between related constructs for the error of measurement in each construct. This is only appropriate if the measure is seen as the expected value of a single underlying construct. However, “under the hood,” SEM programs model the pattern of observed correlations in terms of a measurement (reliability) model as well as a structural (validity) model.
5.5.2 Predicting true scores (and their CIs)
True scores remain unknown and so the reliability coefficient is used in a couple of ways to estimate the true score (and the confidence interval [CI] around that true score).
Take a quick look at the formula for predicting a true score and observe that the reliability coefficient is used within. It generally serves to nudge the observed score a bit closer to the mean: \(T'=(1-r_{xx})\bar{X}+r_{xx}X\)
The CI around that true score includes some estimate of standard error: \(CI_{95}=T'+/-z_{cv}(s_{e})\). Two estimates are commonly used. One is the standard error of estimate \(s_{e}=s_{x}\sqrt{r_{xx}(1-r_{xx})}\) (i.e., the standard deviation of predicted true scores for a given observed score). Another is the standard error of measurement (\(s_{m}=s_{x}\sqrt{(1-r_{xx})}\) (i.e., an estimate of the amount of variation to be expected in test scores; aka, the standard deviation of the errors of measurement).
I can hear you asking What is the difference between \(s_{e}\) and \(s_{m}\)?
- Because \(r_{xx}\) is almost always a fraction, \(s_{e}\) is smaller than \(s_{m}\).
- When the reliability is high, the two standard errors are fairly similar to each other.
- Using \(s_{m}\) will result in wider confidence intervals.
5.5.3 How do I keep it all straight?
Table 1 in Revelle and Condon’s (Revelle & Condon, 2019b) article helps us connect the type of reliability we are seeking with the statistic(s) and the R function within the psych package.
5.6 Practice Problems
In each of these lessons I provide suggestions for practice that allow you to select one or more problems that are graded in difficulty. The practice problems are the start of a larger project that spans multiple lessons. Therefore, if possible, please use a dataset that has item-level data for which there is a theorized total scale score as well as two or more subscales. With each of these options I encourage you to:
- Format (i.e., rescore if necessary) a dataset so that it is possible to calculates estimates of internal consistency
- Calculate and report the alpha coefficient for a total scale scores and subscales (if the scale has them)
- Calculate and report \(\omega_{t}\) and \(\omega_{h}\). With these two determine what proportion of the variance is due to all the factors, error, and g.
- Calculate total and subscale scores.
- Describe other reliability estimates that would be appropriate for the measure you are evaluating.
5.6.1 Problem #1: Play around with this simulation.
If evaluating internal consistency is new to you, copy the script for the simulation and then change (at least) one thing in the simulation to see how it impacts the results. Perhaps you just change the number in “set.seed(210827)” from 210827 to something else. Your results should parallel those obtained in the lecture, making it easier for you to check your work as you go.
5.6.2 Problem #2: Use the data from the live ReCentering Psych Stats survey.
The script below pulls live data directly from the ReCentering Psych Stats survey on Qualtrics. As described in the Scrubbing and Scoring chapters of the ReCentering Psych Stats Multivariate Modeling volume, the Perceptions of the LGBTQ College Campus Climate Scale (Szymanski & Bissonette, 2020) was included (LGBTQ) and further adapted to assess perceptions of campus climate for Black students (BLst), non-Black students of color (nBSoC), international students (INTst), and students disabilities (wDIS). Consider conducting the analyses on one of these scales or merging them together.
library(tidyverse)
# only have to run this ONCE to draw from the same Qualtrics
# account...but will need to get different token if you are changing
# between accounts
library(qualtRics)
# qualtrics_api_credentials(api_key =
# 'mUgPMySYkiWpMFkwHale1QE5HNmh5LRUaA8d9PDg', base_url =
# 'spupsych.az1.qualtrics.com', overwrite = TRUE, install = TRUE)
QTRX_df <- qualtRics::fetch_survey(surveyID = "SV_b2cClqAlLGQ6nLU", time_zone = NULL,
verbose = FALSE, label = FALSE, convert = FALSE, force_request = TRUE,
import_id = FALSE)
climate_df <- QTRX_df %>%
select("Blst_1", "Blst_2", "Blst_3", "Blst_4", "Blst_5", "Blst_6",
"nBSoC_1", "nBSoC_2", "nBSoC_3", "nBSoC_4", "nBSoC_5", "nBSoC_6",
"INTst_1", "INTst_2", "INTst_3", "INTst_4", "INTst_5", "INTst_6",
"wDIS_1", "wDIS_2", "wDIS_3", "wDIS_4", "wDIS_5", "wDIS_6", "LGBTQ_1",
"LGBTQ_2", "LGBTQ_3", "LGBTQ_4", "LGBTQ_5", "LGBTQ_6")
# Item numbers are supported with the following items: _1 'My campus
# unit provides a supportive environment for ___ students' _2
# '________ is visible in my campus unit' _3 'Negative attitudes
# toward persons who are ____ are openly expressed in my campus
# unit.' _4 'My campus unit is unresponsive to the needs of ____
# students.' _5 'Students who are_____ are harassed in my campus
# unit.' _6 'My campus unit is cold and uncaring toward ____
# students.'
# Item 1 on each subscale should be reverse coded. The College
# Response scale is composed of items 1, 4, 6, The Stigma scale is
# composed of items 2,3, 5The optional script below will let you save the simulated data to your computing environment as either a .csv file (think “Excel lite”) or .rds object (preserves any formatting you might do).
5.6.3 Problem #3: Try something entirely new.
Complete the same steps using data for which you have permission and access. This might be data of your own, from your lab, simulated from an article, or located on an open repository.
5.6.4 Grading Rubric
| Assignment Component | Points Possible | Points Earned |
|---|---|---|
| 1. Check and, if needed, format and score data | 5 | _____ |
| 2. Calculate and report the alpha coefficient for a total scale scores and subscales (if the scale has them) | 5 | _____ |
| 3.Calculate and report \(\omega_{t}\) and \(\omega_{h}\). With these two determine what proportion of the variance is due to all the factors, error, and g. | 5 | _____ |
| 4. Calculate total and subscale scores. | 5 | _____ |
| 5.Describe other reliability estimates that would be appropriate for the measure you are evaluating. | 5 | _____ |
| 6. Explanation to grader | 5 | _____ |
| Totals | 30 | _____ |
5.7 Homeworked Example
For more information about the data used in this homeworked example, please refer to the description and codebook located at the end of the introduction in first volume of ReCentering Psych Stats.
As a brief review, this data is part of an IRB-approved study, with consent to use in teaching demonstrations and to be made available to the general public via the open science framework. Hence, it is appropriate to use in this context. You will notice there are student- and teacher- IDs. These numbers are not actual student and teacher IDs, rather they were further re-identified so that they could not be connected to actual people.
Because this is an actual dataset, if you wish to work the problem along with me, you will need to download the ReC.rds data file from the Worked_Examples folder in the ReC_Psychometrics project on the GitHub.
The course evaluation items can be divided into three subscales:
- Valued by the student includes the items: ValObjectives, IncrUnderstanding, IncrInterest
- Traditional pedagogy includes the items: ClearResponsibilities, EffectiveAnswers, Feedback, ClearOrganization, ClearPresentation
- Socially responsive pedagogy includes the items: InclusvClassrm, EquitableEval, MultPerspectives, DEIintegration
In this homework focused on reliability we will report alpha coefficients for total scale score and subscale scores. We’ll also calculate omega total and omega hierarchical and determine what proportion of variance is due to all the factors, error, and g. Finally, we’ll calculate total and subscale scores.
5.7.1 Check and, if needed, format the data
Let’s check the structure…
Classes 'data.table' and 'data.frame': 310 obs. of 33 variables:
$ deID : int 1 2 3 4 5 6 7 8 9 10 ...
$ CourseID : int 57085635 57085635 57085635 57085635 57085635 57085635 57085635 57085635 57085635 57085635 ...
$ Dept : chr "CPY" "CPY" "CPY" "CPY" ...
$ Course : Factor w/ 3 levels "Psychometrics",..: 2 2 2 2 2 2 2 2 2 2 ...
$ StatsPkg : Factor w/ 2 levels "SPSS","R": 2 2 2 2 2 2 2 2 2 2 ...
$ Centering : Factor w/ 2 levels "Pre","Re": 2 2 2 2 2 2 2 2 2 2 ...
$ Year : int 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 ...
$ Quarter : chr "Fall" "Fall" "Fall" "Fall" ...
$ IncrInterest : int 5 3 4 2 4 3 5 3 2 5 ...
$ IncrUnderstanding : int 2 3 4 3 4 4 5 2 4 5 ...
$ ValObjectives : int 5 5 4 4 5 5 5 5 4 5 ...
$ ApprAssignments : int 5 4 4 4 5 3 5 3 3 5 ...
$ EffectiveAnswers : int 5 3 5 3 5 3 4 3 2 3 ...
$ Respectful : int 5 5 4 5 5 4 5 4 5 5 ...
$ ClearResponsibilities : int 5 5 4 4 5 4 5 4 4 5 ...
$ Feedback : int 5 3 4 2 5 NA 5 4 4 5 ...
$ OvInstructor : int 5 4 4 3 5 3 5 4 3 5 ...
$ MultPerspectives : int 5 5 4 5 5 4 5 5 5 5 ...
$ OvCourse : int 3 4 4 3 5 3 5 3 2 5 ...
$ InclusvClassrm : int 5 5 5 5 5 4 5 5 4 5 ...
$ DEIintegration : int 5 5 5 5 5 4 5 5 5 5 ...
$ ClearPresentation : int 4 4 4 2 5 3 4 4 4 5 ...
$ ApprWorkload : int 5 5 3 4 4 2 5 4 4 5 ...
$ MyContribution : int 4 4 4 4 5 4 4 3 4 5 ...
$ InspiredInterest : int 5 3 4 3 5 3 5 4 4 5 ...
$ Faith : int 5 NA 4 2 NA NA 4 4 4 NA ...
$ EquitableEval : int 5 5 3 5 5 3 5 5 3 5 ...
$ SPFC.Decolonize.Opt.Out: chr "" "" "" "" ...
$ ProgramYear : Factor w/ 3 levels "Second","Transition",..: 3 3 3 3 3 3 3 3 3 3 ...
$ ClearOrganization : int 3 4 3 4 4 4 5 4 4 5 ...
$ RegPrepare : int 5 4 4 4 4 3 4 4 4 5 ...
$ EffectiveLearning : int 2 4 3 4 4 2 5 3 2 5 ...
$ AccessibleInstructor : int 5 4 4 4 5 4 5 4 5 5 ...
- attr(*, ".internal.selfref")=<externalptr> Let’s create a df with the items only.
5.7.2 Calculate and report the alpha coefficient for a total scale score and subscales (if the scale has them)
Reliability analysis
Call: psych::alpha(x = items)
raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
0.92 0.92 0.93 0.49 11 0.0065 4.3 0.61 0.48
95% confidence boundaries
lower alpha upper
Feldt 0.90 0.92 0.93
Duhachek 0.91 0.92 0.93
Reliability if an item is dropped:
raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r
ValObjectives 0.92 0.92 0.93 0.51 11.3 0.0067 0.016
IncrUnderstanding 0.91 0.91 0.92 0.49 10.6 0.0070 0.016
IncrInterest 0.91 0.91 0.92 0.49 10.4 0.0070 0.018
ClearResponsibilities 0.91 0.91 0.92 0.48 10.0 0.0073 0.015
EffectiveAnswers 0.91 0.91 0.92 0.48 10.0 0.0074 0.016
Feedback 0.91 0.91 0.92 0.48 10.3 0.0071 0.018
ClearOrganization 0.91 0.91 0.92 0.48 10.2 0.0073 0.016
ClearPresentation 0.91 0.91 0.92 0.47 9.7 0.0076 0.015
MultPerspectives 0.91 0.91 0.92 0.48 10.0 0.0073 0.017
InclusvClassrm 0.91 0.91 0.92 0.49 10.6 0.0069 0.018
DEIintegration 0.92 0.92 0.93 0.52 11.8 0.0063 0.011
EquitableEval 0.91 0.91 0.93 0.49 10.5 0.0070 0.018
med.r
ValObjectives 0.53
IncrUnderstanding 0.50
IncrInterest 0.48
ClearResponsibilities 0.48
EffectiveAnswers 0.48
Feedback 0.48
ClearOrganization 0.48
ClearPresentation 0.47
MultPerspectives 0.47
InclusvClassrm 0.52
DEIintegration 0.53
EquitableEval 0.48
Item statistics
n raw.r std.r r.cor r.drop mean sd
ValObjectives 309 0.59 0.61 0.55 0.53 4.5 0.61
IncrUnderstanding 309 0.71 0.70 0.67 0.64 4.3 0.82
IncrInterest 308 0.75 0.73 0.71 0.68 3.9 0.99
ClearResponsibilities 307 0.80 0.80 0.79 0.75 4.4 0.82
EffectiveAnswers 308 0.80 0.79 0.78 0.75 4.4 0.83
Feedback 304 0.75 0.75 0.72 0.69 4.2 0.88
ClearOrganization 309 0.79 0.77 0.75 0.72 4.0 1.08
ClearPresentation 309 0.85 0.84 0.83 0.80 4.2 0.92
MultPerspectives 305 0.79 0.80 0.78 0.75 4.4 0.84
InclusvClassrm 301 0.68 0.70 0.67 0.62 4.6 0.68
DEIintegration 273 0.51 0.53 0.49 0.42 4.5 0.74
EquitableEval 308 0.70 0.72 0.69 0.66 4.6 0.63
Non missing response frequency for each item
1 2 3 4 5 miss
ValObjectives 0.00 0.01 0.03 0.39 0.57 0.00
IncrUnderstanding 0.01 0.04 0.07 0.44 0.45 0.00
IncrInterest 0.02 0.09 0.14 0.44 0.31 0.01
ClearResponsibilities 0.01 0.02 0.07 0.31 0.59 0.01
EffectiveAnswers 0.01 0.02 0.08 0.36 0.53 0.01
Feedback 0.01 0.05 0.10 0.39 0.46 0.02
ClearOrganization 0.04 0.07 0.10 0.41 0.38 0.00
ClearPresentation 0.02 0.05 0.07 0.40 0.46 0.00
MultPerspectives 0.02 0.02 0.08 0.33 0.56 0.02
InclusvClassrm 0.01 0.01 0.05 0.23 0.70 0.03
DEIintegration 0.00 0.01 0.10 0.22 0.67 0.12
EquitableEval 0.00 0.01 0.03 0.32 0.63 0.01Total scale score alpha is 0.92
5.7.3 Subscale alphas
In the lecture, I created baby dfs of the subscales and ran the alpha on those; another option is to use concatenated lists of variables (i.e., variable vectors). Later, we can also use these to score the subscales.
ValuedVars <- c("ValObjectives", "IncrUnderstanding", "IncrInterest")
TradPedVars <- c("ClearResponsibilities", "EffectiveAnswers", "Feedback",
"ClearOrganization", "ClearPresentation")
SRPedVars <- c("InclusvClassrm", "EquitableEval", "MultPerspectives", "DEIintegration")
Reliability analysis
Call: psych::alpha(x = items[, ValuedVars])
raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
0.77 0.77 0.71 0.53 3.4 0.02 4.2 0.68 0.48
95% confidence boundaries
lower alpha upper
Feldt 0.72 0.77 0.81
Duhachek 0.73 0.77 0.81
Reliability if an item is dropped:
raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r
ValObjectives 0.80 0.81 0.68 0.68 4.3 0.022 NA
IncrUnderstanding 0.60 0.65 0.48 0.48 1.8 0.040 NA
IncrInterest 0.59 0.61 0.44 0.44 1.6 0.044 NA
med.r
ValObjectives 0.68
IncrUnderstanding 0.48
IncrInterest 0.44
Item statistics
n raw.r std.r r.cor r.drop mean sd
ValObjectives 309 0.71 0.77 0.55 0.50 4.5 0.61
IncrUnderstanding 309 0.86 0.85 0.76 0.68 4.3 0.82
IncrInterest 308 0.90 0.87 0.79 0.70 3.9 0.99
Non missing response frequency for each item
1 2 3 4 5 miss
ValObjectives 0.00 0.01 0.03 0.39 0.57 0.00
IncrUnderstanding 0.01 0.04 0.07 0.44 0.45 0.00
IncrInterest 0.02 0.09 0.14 0.44 0.31 0.01Alpha for the Valued-by-Me dimension is .77
Reliability analysis
Call: psych::alpha(x = items[, TradPedVars])
raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
0.89 0.9 0.88 0.64 8.8 0.0094 4.3 0.76 0.65
95% confidence boundaries
lower alpha upper
Feldt 0.87 0.89 0.91
Duhachek 0.88 0.89 0.91
Reliability if an item is dropped:
raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r
ClearResponsibilities 0.86 0.86 0.84 0.62 6.4 0.013 0.0054
EffectiveAnswers 0.87 0.87 0.84 0.63 6.8 0.012 0.0045
Feedback 0.89 0.89 0.87 0.68 8.4 0.010 0.0016
ClearOrganization 0.88 0.88 0.85 0.64 7.2 0.012 0.0044
ClearPresentation 0.86 0.87 0.83 0.62 6.5 0.013 0.0030
med.r
ClearResponsibilities 0.59
EffectiveAnswers 0.65
Feedback 0.69
ClearOrganization 0.66
ClearPresentation 0.62
Item statistics
n raw.r std.r r.cor r.drop mean sd
ClearResponsibilities 307 0.87 0.87 0.84 0.79 4.4 0.82
EffectiveAnswers 308 0.84 0.85 0.81 0.76 4.4 0.83
Feedback 304 0.78 0.79 0.70 0.66 4.2 0.88
ClearOrganization 309 0.85 0.83 0.78 0.74 4.0 1.08
ClearPresentation 309 0.87 0.87 0.83 0.78 4.2 0.92
Non missing response frequency for each item
1 2 3 4 5 miss
ClearResponsibilities 0.01 0.02 0.07 0.31 0.59 0.01
EffectiveAnswers 0.01 0.02 0.08 0.36 0.53 0.01
Feedback 0.01 0.05 0.10 0.39 0.46 0.02
ClearOrganization 0.04 0.07 0.10 0.41 0.38 0.00
ClearPresentation 0.02 0.05 0.07 0.40 0.46 0.00Alpha for Traditional Pedagogy dimension is .90
Reliability analysis
Call: psych::alpha(x = items[, SRPedVars])
raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
0.81 0.81 0.78 0.52 4.3 0.017 4.5 0.58 0.54
95% confidence boundaries
lower alpha upper
Feldt 0.77 0.81 0.84
Duhachek 0.77 0.81 0.84
Reliability if an item is dropped:
raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r
InclusvClassrm 0.74 0.74 0.67 0.49 2.9 0.025 0.0120
EquitableEval 0.78 0.79 0.73 0.56 3.9 0.021 0.0034
MultPerspectives 0.73 0.74 0.67 0.49 2.8 0.026 0.0153
DEIintegration 0.78 0.78 0.71 0.54 3.6 0.021 0.0044
med.r
InclusvClassrm 0.50
EquitableEval 0.57
MultPerspectives 0.47
DEIintegration 0.57
Item statistics
n raw.r std.r r.cor r.drop mean sd
InclusvClassrm 301 0.82 0.83 0.76 0.67 4.6 0.68
EquitableEval 308 0.75 0.76 0.64 0.58 4.6 0.63
MultPerspectives 305 0.85 0.83 0.76 0.68 4.4 0.84
DEIintegration 273 0.78 0.78 0.67 0.59 4.5 0.74
Non missing response frequency for each item
1 2 3 4 5 miss
InclusvClassrm 0.01 0.01 0.05 0.23 0.70 0.03
EquitableEval 0.00 0.01 0.03 0.32 0.63 0.01
MultPerspectives 0.02 0.02 0.08 0.33 0.56 0.02
DEIintegration 0.00 0.01 0.10 0.22 0.67 0.12Alpha for the SCR Pedagogy dimension is .81
5.7.4 Calculate and report ωt and ωh
Warning in lav_model_vcov(lavmodel = lavmodel, lavsamplestats = lavsamplestats, : lavaan WARNING:
Could not compute standard errors! The information matrix could
not be inverted. This may be a symptom that the model is not
identified.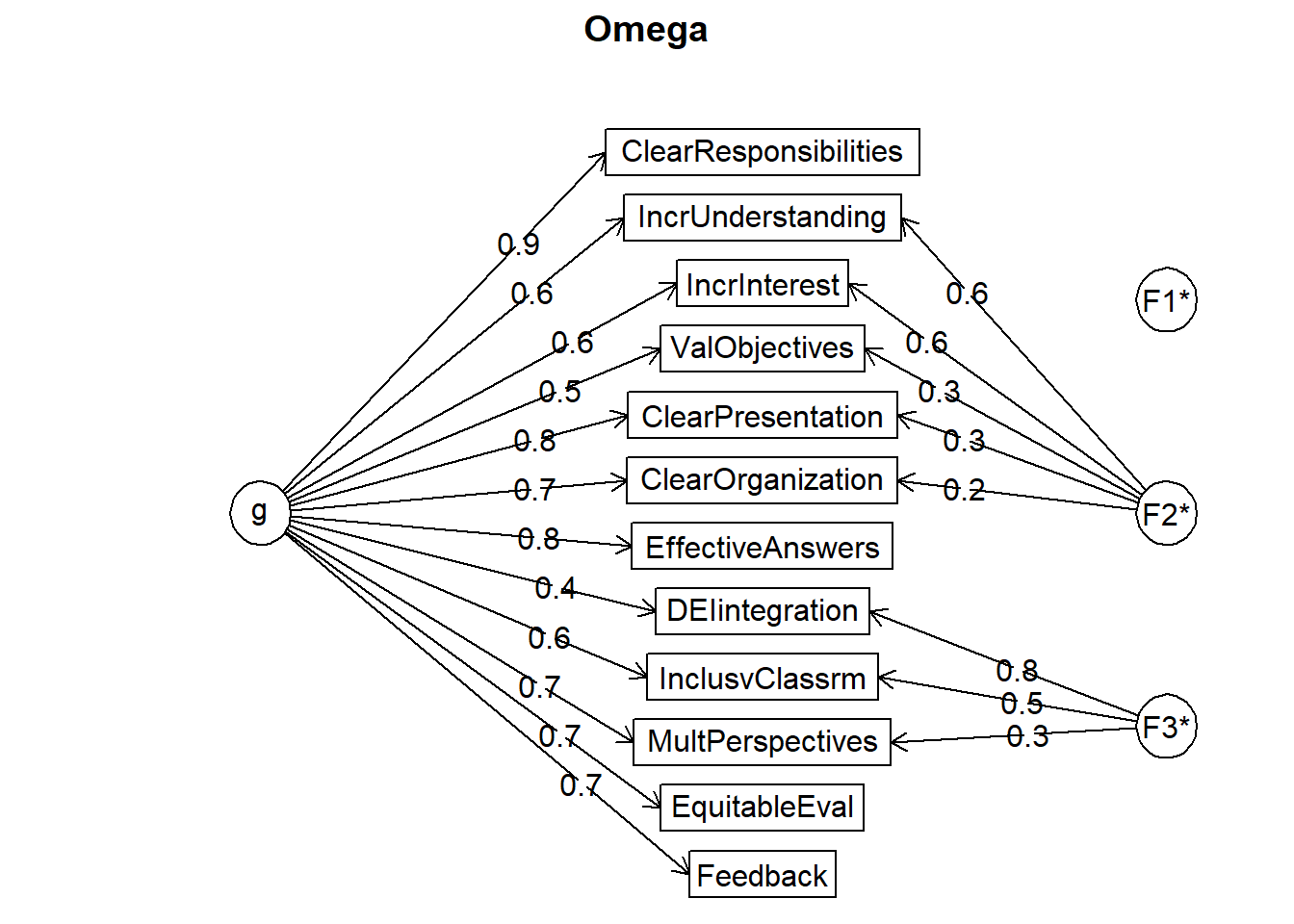
Call: psych::omegaSem(m = items, nfactors = 3)
Omega
Call: omegah(m = m, nfactors = nfactors, fm = fm, key = key, flip = flip,
digits = digits, title = title, sl = sl, labels = labels,
plot = plot, n.obs = n.obs, rotate = rotate, Phi = Phi, option = option,
covar = covar)
Alpha: 0.92
G.6: 0.93
Omega Hierarchical: 0.83
Omega H asymptotic: 0.88
Omega Total 0.94
Schmid Leiman Factor loadings greater than 0.2
g F1* F2* F3* h2 u2 p2
ValObjectives 0.47 0.32 0.33 0.67 0.67
IncrUnderstanding 0.57 0.60 0.69 0.31 0.47
IncrInterest 0.58 0.57 0.67 0.33 0.49
ClearResponsibilities 0.87 0.78 0.22 0.98
EffectiveAnswers 0.79 0.65 0.35 0.97
Feedback 0.73 0.56 0.44 0.96
ClearOrganization 0.75 0.23 0.62 0.38 0.90
ClearPresentation 0.81 0.30 0.74 0.26 0.88
MultPerspectives 0.75 0.30 0.65 0.35 0.86
InclusvClassrm 0.56 0.48 0.57 0.43 0.55
DEIintegration 0.37 0.82 0.80 0.20 0.17
EquitableEval 0.70 0.52 0.48 0.94
With Sums of squares of:
g F1* F2* F3*
5.51 0.04 0.98 1.06
general/max 5.19 max/min = 26.42
mean percent general = 0.74 with sd = 0.26 and cv of 0.36
Explained Common Variance of the general factor = 0.73
The degrees of freedom are 33 and the fit is 0.25
The number of observations was 310 with Chi Square = 76.65 with prob < 0.000025
The root mean square of the residuals is 0.02
The df corrected root mean square of the residuals is 0.03
RMSEA index = 0.065 and the 10 % confidence intervals are 0.046 0.085
BIC = -112.66
Compare this with the adequacy of just a general factor and no group factors
The degrees of freedom for just the general factor are 54 and the fit is 1.37
The number of observations was 310 with Chi Square = 415 with prob < 0.0000000000000000000000000000000000000000000000000000000038
The root mean square of the residuals is 0.1
The df corrected root mean square of the residuals is 0.11
RMSEA index = 0.147 and the 10 % confidence intervals are 0.134 0.16
BIC = 105.22
Measures of factor score adequacy
g F1* F2* F3*
Correlation of scores with factors 0.95 0.13 0.81 0.89
Multiple R square of scores with factors 0.91 0.02 0.66 0.79
Minimum correlation of factor score estimates 0.82 -0.96 0.32 0.58
Total, General and Subset omega for each subset
g F1* F2* F3*
Omega total for total scores and subscales 0.94 0.77 0.90 0.87
Omega general for total scores and subscales 0.83 0.76 0.69 0.64
Omega group for total scores and subscales 0.11 0.01 0.20 0.23
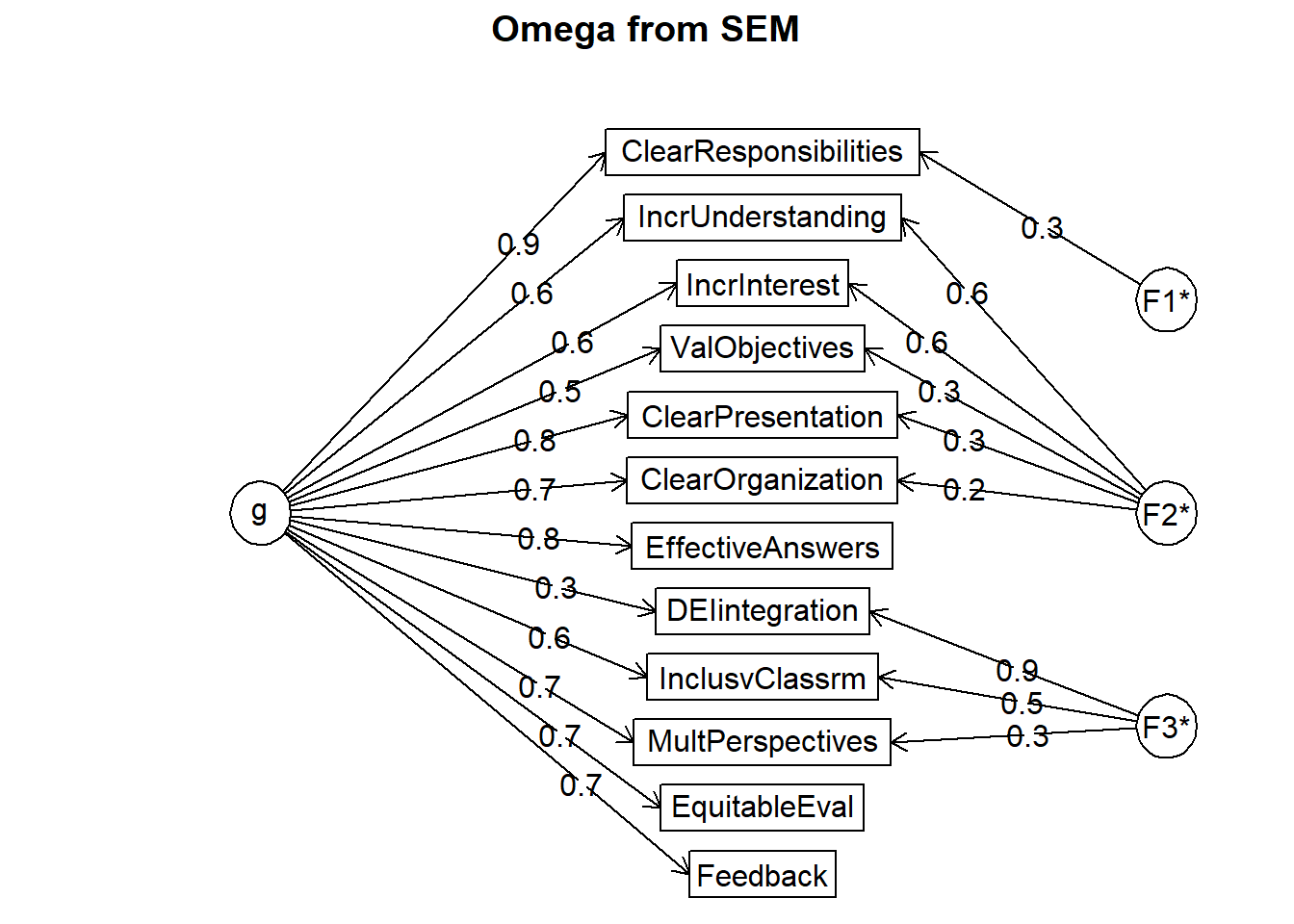
The following analyses were done using the lavaan package
Omega Hierarchical from a confirmatory model using sem = 0.82
Omega Total from a confirmatory model using sem = 0.94
With loadings of
g F1* F2* F3* h2 u2 p2
ValObjectives 0.47 0.32 0.33 0.67 0.67
IncrUnderstanding 0.56 0.62 0.70 0.30 0.45
IncrInterest 0.57 0.56 0.64 0.36 0.51
ClearResponsibilities 0.86 0.32 0.84 0.16 0.88
EffectiveAnswers 0.80 0.65 0.35 0.98
Feedback 0.73 0.55 0.45 0.97
ClearOrganization 0.75 0.22 0.61 0.39 0.92
ClearPresentation 0.82 0.27 0.74 0.26 0.91
MultPerspectives 0.74 0.30 0.64 0.36 0.86
InclusvClassrm 0.56 0.49 0.56 0.44 0.56
DEIintegration 0.33 0.87 0.87 0.13 0.13
EquitableEval 0.69 0.51 0.49 0.93
With sum of squared loadings of:
g F1* F2* F3*
5.46 0.10 0.94 1.14
The degrees of freedom of the confirmatory model are 42 and the fit is 110.6184 with p = 0.00000004343729
general/max 4.8 max/min = 10.87
mean percent general = 0.73 with sd = 0.27 and cv of 0.37
Explained Common Variance of the general factor = 0.71
Measures of factor score adequacy
g F1* F2* F3*
Correlation of scores with factors 0.95 0.57 0.82 0.95
Multiple R square of scores with factors 0.91 0.32 0.67 0.90
Minimum correlation of factor score estimates 0.82 -0.36 0.35 0.80
Total, General and Subset omega for each subset
g F1* F2* F3*
Omega total for total scores and subscales 0.94 0.84 0.89 0.87
Omega general for total scores and subscales 0.82 0.74 0.70 0.62
Omega group for total scores and subscales 0.11 0.10 0.20 0.26
To get the standard sem fit statistics, ask for summary on the fitted objectI’m reporting the values below the statement, “The following analyses were done using the lavaan package”:
Omega total = .94 (omega total values > .80 are an indicator of good reliability). Interpretation: 94% of the variance in the total scale is due to the factors and the balance (6%) is due to error.
Omega hierarchical estimates the proportion of variance in the overall course evaluation score attributable to the general factors (thus treating the subscales as error). Omega h for the overall course evaluation score was .82
5.7.5 With these two determine what proportion of the variance is due to all the factors, error, and g.
[1] 0.8723404A quick calculation with omega h (.82) and omega total (.94) lets us know that 87% of the reliable variance in the overall course evaluation score is attributable to the general factor.
5.7.6 Calculate total and subscale scores.
This code uses the variable vectors I created above.
items$Valued <- sjstats::mean_n(items[, ValuedVars], 0.75)
items$TradPed <- sjstats::mean_n(items[, TradPedVars], 0.75)
items$SCRPed <- sjstats::mean_n(items[, SRPedVars], 0.75)
items$Total <- sjstats::mean_n(items, 0.75) vars n mean sd median trimmed mad min max range skew kurtosis
Valued 1 309 4.25 0.68 4.33 4.32 0.50 1.67 5 3.33 -0.90 0.57
TradPed 2 307 4.25 0.76 4.40 4.37 0.59 1.00 5 4.00 -1.42 2.48
SCRPed 3 299 4.52 0.58 4.75 4.61 0.37 2.25 5 2.75 -1.25 1.33
Total 4 308 4.34 0.60 4.41 4.41 0.62 1.83 5 3.17 -1.07 1.12
se
Valued 0.04
TradPed 0.04
SCRPed 0.03
Total 0.035.7.7 Describe other reliability estimates that would be appropriate for the measure you are evaluating.
These scales are for the purposes of course evaluations. In their development, it might be helpful to give it at the end of a single course and then again a few weeks later to determine test-retest reliability.