Chapter 9 Principal Axis Factoring
This is the second lesson of exploratory principal components analysis (PCA) and factor analysis (EFA/PAF). This time the focus is on actual factor analysis. There are numerous approaches to this process (e.g., principal components analysis, parallel analyses). In this lesson I will demonstrate principal axis factoring (PAF).
9.2 Exploratory Factor Analysis (with a quick contrast to PCA)
Whereas principal components analysis (PCA) is a regression analysis technique, principal factor analysis is a latent variable model (revelle_william_chapter_nodate?).
Exploratory factor analysis has a rich history. In 1904, Spearman used it for a single factor. In 1947, Thurstone generalized it to multiple factors. Factor analysis is frequently used and controversial.
Factor analysis and principal components are commonly confused:
Principal components is
- linear sums of variables,
- solved with an eigenvalue or singular decomposition,
- represented by an \(n*n\) matrix in terms of the first k components and attempts to reproduce all of the \(R\) matrix, and
- paths which point from the items to a total scale score – all represented as observed/manifest (square) variables.
Factor analysis is
- linear sums of unknown factors,
- estimated as best fitting solutions, normally through iterative procedures, and
- controversial. Because:
- At the structural level (i.e., covariance or correlation matrix), there are normally more observed variables than parameters to estimate them and the procedure seeks to find the best fitting solution using ordinary least squares, weighted least squares, or maximum likelihood.
- At the data level, although scores can be estimated, the model is indeterminate.
- This leads some to argue for using principal components; however, fans of factor analysis suggest that it is useful for constructing and evaluating theories.
- an attempt to model only the common part of the matrix, which means all of the off-diagonal elements and the common part of the diagonal (the communalities); the uniquenesses are the non-common (leftover) part
- Stated another way, the factor model partitions the correlation or covariance matrix into
- common factors, \(FF'\), and
- that which is unique, \(U^2\) (the diagonal matrix of uniquenesses)
- Stated another way, the factor model partitions the correlation or covariance matrix into
- paths which point from the latent variable (LV) representing the factor (oval) to the items (squares) illustrating that the factor/LV “causes” the item’s score
Our focus today is on the PAF approach to scale construction. By utilizing the same research vignette as in the PCA lesson, we can identify similarities in differences in the approach, results, and interpretation. Let’s first take a look at the workflow for PAF.
9.3 PAF Workflow
Below is a screenshot of the workflow. The original document is located in the GitHub site that hosts the ReCentering Psych Stats: Psychometrics OER. You may find it refreshing that, with the exception of the change from “components” to “factors,” the workflow for PCA and PAF are quite similar.

Steps in the process include:
- Creating an items only dataframe where all items are scaled in the same direction (i.e., negatively worded items are reverse scored).
- Conducting tests that assess the statistical assumptions of PAF to ensure that the data is appropriate for PAF.
- Determining the number of factors (think “subscales”) to extract.
- Conducting the factor extraction – this process will likely occur iteratively,
- exploring orthogonal (uncorrelated/independent) and oblique (correlated) factors, and
- changing the number of factors to extract
Because the intended audience for the ReCentering Psych Stats OER is the scientist-practitioner-advocate, this lesson focuses on the workflow and decisions. As you might guess, the details of PAF can be quite complex. Some important notions to consider that may not be obvious from lesson, are these:
- The values of factor loadings are directly related to the correlation matrix.
- Although I do not explain this in detail, nearly every analytic step attempts to convey this notion by presenting equivalent analytic options using the raw data and correlation matrix.
- PAF (like PCA and related EFA procedures) is about dimension reduction – our goal is fewer factors (think subscales) than there are items.
- In this lesson’s vignette there are 25 items on the scale, and we will have 4 subscales.
- As a latent variable procedure, PAF is both exploratory and factor analysis. This is in contrast to our prior PCA lesson. Recall that PCA is a regression-based model and therefore not “factor analysis.”
- Matrix algebra (e.g., using the transpose of a matrix, multiplying matrices together) plays a critical role in the analytic solution.
9.4 Research Vignette
This lesson’s research vignette emerges from Lewis and Neville’s Gendered Racial Microaggressions Scale for Black Women (2015). The article reports on two separate studies that comprised the development, refinement, and psychometric evaluation of two parallel versions (stress appraisal, frequency) of the scale. Below, I simulate data from the final construction of the stress appraisal version as the basis of the lecture. Items were on a 6-point Likert scale ranging from 0 (not at all stressful) to 5 (extremely stressful).
Lewis and Neville (2015) reported support for a total scale score (25 items) and four subscales. Below, I list the four subscales along with the items and their abbreviation. At the outset, let me provide a content advisory. For those who hold this particular identity (or related identities) the content in the items may be upsetting. In other lessons, I often provide a variable name that gives an indication of the primary content of the item. In the case of the GRMS, I will simply provide an abbreviation of the subscale name and its respective item number. This will allow us to easily inspect the alignment of the item with its intended factor, and hopefully minimize discomfort.
If you are not a member of this particular identity, I encourage you to learn about these microaggressions by reading the article in its entirety. Please do not ask members of this group to explain why these microaggressions are harmful or ask if they have encountered them. The four factors, number of items, and sample item are as follows:
- Assumptions of Beauty and Sexual Objectification (10 items)
- Unattractive because of size of butt (Obj1)
- Negative comments about size of facial features (Obj2)
- Imitated the way they think Black women speak (Obj3)
- Someone made me feel unattractive (Obj4)
- Negative comment about skin tone (Obj5)
- Someone assumed I speak a certain way (Obj6)
- Objectified me based on physical features(Obj7)
- Someone assumed I have a certain body type (Obj8; stress only)
- Made a sexually inappropriate comment (Obj9)
- Negative comments about my hair when natural (Obj10)
- Assumed I was sexually promiscuous (frequency only; not used in this simulation)
- Silenced and Marginalized (7 items)
- I have felt unheard (Marg1)
- My comments have been ignored (Marg2)
- Someone challenged my authority (Marg3)
- I have been disrespected in workplace (Marg4)
- Someone has tried to “put me in my place” (Marg5)
- Felt excluded from networking opportunities (Marg6)
- Assumed I did not have much to contribute to the conversation (Marg7)
- Strong Black Woman Stereotype (5 items)
- Someone assumed I was sassy and straightforward (Str1; stress only)
- I have been told that I am too independent (Str2)
- Someone made me feel exotic as a Black woman (Str2; stress only)
- I have been told that I am too assertive
- Assumed to be a strong Black woman
- Angry Black Woman Stereotype (3 items)
- Someone has told me to calm down (Ang1)
- Perceived to be “angry Black woman” (Ang2)
- Someone accused me of being angry when speaking calm (Ang3)
Three additional scales were reported in the Lewis and Neville article (2015). Because (a) the focus of this lesson is on exploratory factor analytic approaches and, therefore, only requires item-level data for the scale, and (b) the article does not include correlations between the subscales/scales of all involved measures, I only simulated item-level data for the GRMS items.
Below, I walk through the data simulation. This is not an essential portion of the lesson, but I will lecture it in case you are interested. None of the items are negatively worded (relative to the other items), so there is no need to reverse-score any items.
Simulating the data involved using factor loadings, means, standard deviations, and correlations between the scales. Because the simulation will produce “out-of-bounds” values, the code below rescales the scores into the range of the Likert-type scaling and rounds them to whole values.
# Entering the intercorrelations means and standard deviations from
# the journal article
LewisGRMS_generating_model <- "
#measurement model
Objectification =~ .69*Obj1 + .69*Obj2 + .60*Obj3 + .59*Obj4 + .55*Obj5 + .55*Obj6 + .54*Obj7 + .50*Obj8 + .41*Obj9 + .41*Obj10
Marginalized =~ .93*Marg1 + .81*Marg2 +.69*Marg3 + .67*Marg4 + .61*Marg5 + .58*Marg6 +.54*Marg7
Strong =~ .59*Str1 + .55*Str2 + .54*Str3 + .54*Str4 + .51*Str5
Angry =~ .70*Ang1 + .69*Ang2 + .68*Ang3
#Means
Objectification ~ 1.85*1
Marginalized ~ 2.67*1
Strong ~ 1.61*1
Angry ~ 2.29*1
#Correlations
Objectification ~~ .63*Marginalized
Objectification ~~ .66*Strong
Objectification ~~ .51*Angry
Marginalized ~~ .59*Strong
Marginalized ~~ .62*Angry
Strong ~~ .61*Angry
"
set.seed(240311)
dfGRMS <- lavaan::simulateData(model = LewisGRMS_generating_model, model.type = "sem",
meanstructure = T, sample.nobs = 259, standardized = FALSE)
# used to retrieve column indices used in the rescaling script below
col_index <- as.data.frame(colnames(dfGRMS))
# The code below loops through each column of the dataframe and
# assigns the scaling accordingly Rows 1 thru 26 are the GRMS items
for (i in 1:ncol(dfGRMS)) {
if (i >= 1 & i <= 25) {
dfGRMS[, i] <- scales::rescale(dfGRMS[, i], c(0, 5))
}
}
# rounding to integers so that the data resembles that which was
# collected
library(tidyverse)
dfGRMS <- dfGRMS %>%
round(0)
# quick check psych::describe(dfGRMS)The optional script below will let you save the simulated data to your computing environment as either an .rds object (preserves any formatting you might do) or a .csv file (think “Excel lite”).
An .rds file preserves all formatting to variables prior to the export and re-import. For the purpose of this chapter, you don’t need to do either. That is, you can re-simulate the data each time you work the problem.
# to save the df as an .rds (think 'R object') file on your computer;
# it should save in the same file as the .rmd file you are working
# with saveRDS(dfGRMS, 'dfGRMS.rds') bring back the simulated dat
# from an .rds file dfGRMS <- readRDS('dfGRMS.rds')If you save the .csv file and bring it back in, you will lose any formatting (e.g., ordered factors will be interpreted as character variables).
# write the simulated data as a .csv write.table(dfGRMS,
# file='dfGRMS.csv', sep=',', col.names=TRUE, row.names=FALSE) bring
# back the simulated dat from a .csv file dfGRMS <- read.csv
# ('dfGRMS.csv', header = TRUE)Before moving on, I want to acknowledge that (at their first drafting), I try to select research vignettes that have been published within the prior 5 years. With a publication date of 2015, this article clearly falls outside that range. I have continued to include it because (a) the scholarship is superior – especially as the measure captures an intersectional identity, (b) the article has been a model for research that follows (e.g., Keum et al’s (2018) Gendered Racial Microaggression Scale for Asian American Women), and (c) there is often a time lag between the initial publication of a psychometric scale and its use. A key reason I have retained the GRMS as a psychometrics research vignette is that in ReCentering Psych Stats: Multivariate Modeling, GRMS scales are used in a couple of more recently published research vignettes.
9.5 Working the Vignette
It may be useful to recall how we might understand factors in the psychometric sense:
- clusters of correlated items in an \(R\)-matrix
- statistical entities that can be plotted as classification axes where coordinates of variables along each axis represent the strength of the relationship between that variable to each factor.
- mathematical equations, resembling regression equations, where each variable is represented according to its relative weight
9.5.1 Data Prep
Since the first step is data preparation, let’s start by:
- reverse coding any items that are phrased in the opposite direction
- creating a df (as an object) that only contains the items in their properly scored direction (i.e., you might need to replace the original item with the reverse-coded item); there should be no other variables (e.g., ID, demographic variables, other scales) in this df
- because the GRMS has no items like this we can skip these two steps
Our example today requires no reverse coding and the dataset I simulated only has item-level data (with no ID and no other variables). This means we are ready to start the PAF process.
Let’s take a look at (and make an object of) the correlation matrix.
GRMSr <- cor(dfGRMS) #correlation matrix (with the negatively scored item already reversed) created and saved as object
round(GRMSr, 2) Obj1 Obj2 Obj3 Obj4 Obj5 Obj6 Obj7 Obj8 Obj9 Obj10 Marg1 Marg2 Marg3
Obj1 1.00 0.35 0.25 0.27 0.28 0.25 0.28 0.35 0.15 0.24 0.19 0.25 0.17
Obj2 0.35 1.00 0.31 0.25 0.27 0.23 0.31 0.28 0.26 0.24 0.22 0.21 0.25
Obj3 0.25 0.31 1.00 0.24 0.28 0.28 0.20 0.25 0.21 0.22 0.17 0.23 0.17
Obj4 0.27 0.25 0.24 1.00 0.39 0.23 0.28 0.30 0.26 0.28 0.22 0.18 0.14
Obj5 0.28 0.27 0.28 0.39 1.00 0.15 0.18 0.29 0.25 0.20 0.17 0.20 0.23
Obj6 0.25 0.23 0.28 0.23 0.15 1.00 0.20 0.14 0.21 0.12 0.10 0.14 0.05
Obj7 0.28 0.31 0.20 0.28 0.18 0.20 1.00 0.31 0.19 0.28 0.30 0.21 0.20
Obj8 0.35 0.28 0.25 0.30 0.29 0.14 0.31 1.00 0.19 0.23 0.27 0.14 0.14
Obj9 0.15 0.26 0.21 0.26 0.25 0.21 0.19 0.19 1.00 0.20 0.10 0.12 0.21
Obj10 0.24 0.24 0.22 0.28 0.20 0.12 0.28 0.23 0.20 1.00 0.09 0.12 0.17
Marg1 0.19 0.22 0.17 0.22 0.17 0.10 0.30 0.27 0.10 0.09 1.00 0.43 0.41
Marg2 0.25 0.21 0.23 0.18 0.20 0.14 0.21 0.14 0.12 0.12 0.43 1.00 0.35
Marg3 0.17 0.25 0.17 0.14 0.23 0.05 0.20 0.14 0.21 0.17 0.41 0.35 1.00
Marg4 0.19 0.18 0.24 0.26 0.20 0.10 0.25 0.24 0.07 0.12 0.38 0.23 0.32
Marg5 0.17 0.22 0.21 0.27 0.25 0.16 0.23 0.19 0.19 0.11 0.41 0.40 0.25
Marg6 0.18 0.27 0.16 0.23 0.22 0.26 0.28 0.26 0.15 0.26 0.35 0.27 0.25
Marg7 0.13 0.19 0.14 0.19 0.06 0.17 0.16 0.14 0.10 0.11 0.31 0.33 0.20
Str1 0.22 0.18 0.14 0.06 0.23 0.07 0.25 0.17 0.19 0.10 0.19 0.25 0.20
Str2 0.19 0.18 0.19 0.19 0.12 0.15 0.13 0.06 0.18 0.19 0.12 0.18 0.17
Str3 0.10 0.09 0.09 0.08 0.11 0.09 0.19 0.05 0.12 0.10 0.13 0.18 0.10
Str4 0.09 0.14 0.18 0.15 0.12 0.08 0.07 0.13 0.05 0.02 0.08 0.12 0.08
Str5 0.20 0.15 0.15 0.08 0.19 0.11 0.15 0.04 0.07 0.09 0.10 0.23 0.12
Ang1 0.06 0.07 0.07 0.09 0.12 0.04 0.15 0.07 0.17 0.06 0.16 0.23 0.18
Ang2 0.06 0.15 0.08 0.06 0.09 0.20 0.13 -0.03 0.00 0.14 0.17 0.19 0.19
Ang3 0.21 0.13 0.11 0.14 0.11 0.16 0.23 0.07 0.06 0.08 0.28 0.28 0.11
Marg4 Marg5 Marg6 Marg7 Str1 Str2 Str3 Str4 Str5 Ang1 Ang2 Ang3
Obj1 0.19 0.17 0.18 0.13 0.22 0.19 0.10 0.09 0.20 0.06 0.06 0.21
Obj2 0.18 0.22 0.27 0.19 0.18 0.18 0.09 0.14 0.15 0.07 0.15 0.13
Obj3 0.24 0.21 0.16 0.14 0.14 0.19 0.09 0.18 0.15 0.07 0.08 0.11
Obj4 0.26 0.27 0.23 0.19 0.06 0.19 0.08 0.15 0.08 0.09 0.06 0.14
Obj5 0.20 0.25 0.22 0.06 0.23 0.12 0.11 0.12 0.19 0.12 0.09 0.11
Obj6 0.10 0.16 0.26 0.17 0.07 0.15 0.09 0.08 0.11 0.04 0.20 0.16
Obj7 0.25 0.23 0.28 0.16 0.25 0.13 0.19 0.07 0.15 0.15 0.13 0.23
Obj8 0.24 0.19 0.26 0.14 0.17 0.06 0.05 0.13 0.04 0.07 -0.03 0.07
Obj9 0.07 0.19 0.15 0.10 0.19 0.18 0.12 0.05 0.07 0.17 0.00 0.06
Obj10 0.12 0.11 0.26 0.11 0.10 0.19 0.10 0.02 0.09 0.06 0.14 0.08
Marg1 0.38 0.41 0.35 0.31 0.19 0.12 0.13 0.08 0.10 0.16 0.17 0.28
Marg2 0.23 0.40 0.27 0.33 0.25 0.18 0.18 0.12 0.23 0.23 0.19 0.28
Marg3 0.32 0.25 0.25 0.20 0.20 0.17 0.10 0.08 0.12 0.18 0.19 0.11
Marg4 1.00 0.30 0.26 0.16 0.10 0.21 0.05 0.06 0.03 0.12 0.22 0.17
Marg5 0.30 1.00 0.29 0.28 0.16 0.13 0.16 0.14 0.18 0.12 0.14 0.21
Marg6 0.26 0.29 1.00 0.20 0.13 0.18 0.15 0.13 0.08 0.11 0.21 0.12
Marg7 0.16 0.28 0.20 1.00 0.14 0.05 0.04 0.02 0.12 0.17 0.13 0.09
Str1 0.10 0.16 0.13 0.14 1.00 0.21 0.30 0.23 0.23 0.18 0.05 0.10
Str2 0.21 0.13 0.18 0.05 0.21 1.00 0.20 0.20 0.12 0.16 0.12 0.16
Str3 0.05 0.16 0.15 0.04 0.30 0.20 1.00 0.27 0.18 0.20 0.07 0.15
Str4 0.06 0.14 0.13 0.02 0.23 0.20 0.27 1.00 0.12 0.15 0.03 0.02
Str5 0.03 0.18 0.08 0.12 0.23 0.12 0.18 0.12 1.00 0.22 0.15 0.11
Ang1 0.12 0.12 0.11 0.17 0.18 0.16 0.20 0.15 0.22 1.00 0.24 0.23
Ang2 0.22 0.14 0.21 0.13 0.05 0.12 0.07 0.03 0.15 0.24 1.00 0.25
Ang3 0.17 0.21 0.12 0.09 0.10 0.16 0.15 0.02 0.11 0.23 0.25 1.00In case you want to examine it in sections (easier to view):
As with PCA, we can analyze the data with either raw data or correlation matrix. I will do both to demonstrate (a) that it’s possible and to (b) continue emphasizing that this is a structural analysis. That is, we are trying to see if our more parsimonious extraction reproduces this original correlation matrix.
9.5.1.1 Three Diagnostic Tests to Evaluate the Appropriateness of the Data for Factor (or Component))Analysis
Here’s a snip of our location in the PAF workflow.

9.5.1.1.1 Is my sample adequate for PAF?
We return to the KMO (Kaiser-Meyer-Olkin), an index of sampling adequacy that can be used with the actual sample to let us know if the sample size is sufficient (or if we should collect more data).
Kaiser’s 1974 recommendations were:
- bare minimum of .5
- values between .5 and .7 are mediocre
- values between .7 and .8 are good
- values above .9 are superb
We use the KMO() function from the psych package with either raw or matrix dat.
Kaiser-Meyer-Olkin factor adequacy
Call: psych::KMO(r = dfGRMS)
Overall MSA = 0.85
MSA for each item =
Obj1 Obj2 Obj3 Obj4 Obj5 Obj6 Obj7 Obj8 Obj9 Obj10 Marg1 Marg2 Marg3
0.87 0.91 0.88 0.85 0.85 0.80 0.90 0.85 0.81 0.85 0.86 0.89 0.86
Marg4 Marg5 Marg6 Marg7 Str1 Str2 Str3 Str4 Str5 Ang1 Ang2 Ang3
0.86 0.90 0.89 0.84 0.83 0.85 0.82 0.74 0.84 0.78 0.76 0.81 # psych::KMO(GRMSr) #for the KMO function, do not specify sample size
# if using the matrix form of the dataWe examine the KMO values for both the overall matrix and the individual items.
At the matrix level, our \(KMO = .85\), which falls in between Kaiser’s definitions of good and superb.
At the item level, the KMO should be > .50. Variables with values below .5 should be evaluated for exclusion from the analysis (or run the analysis with and without the variable and compare the difference). Because removing/adding variables impacts the KMO, be sure to re-evaluate.
At the item level, our KMO values range between .74 (Str4) and .91 (Obj2).
Considering both item- and matrix- levels, we conclude that the sample size and the data are adequate for factor (or component) analysis.
9.5.1.1.2 Are the correlations among the variables big enough to be analyzed?
Bartlett’s lets us know if a matrix is an identity matrix. In an identity matrix all correlation coefficients (everything on the off-diagonal) would be 0.0 (and everything on the diagonal would be 1.0).
A significant Barlett’s (i.e., \(p < .05\)) tells that the \(R\)-matrix is not an identity matrix. That is, there are some relationships between variables that can be analyzed.
The cortest.bartlett() function in the psych package and can be run either from the raw data or R matrix formats.
R was not square, finding R from data$chisq
[1] 1217.508
$p.value
[1] 0.00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001107085
$df
[1] 300# raw data produces the warning 'R was not square, finding R from
# data.' This means nothing other than we fed it raw data and the
# function is creating a matrix from which to do the analysis.
# psych::cortest.bartlett(GRMSr, n = 259) #if using the matrix, must
# specify sample sizeOur Bartlett’s test is significant: \(\chi^{2}(300)=1217.508, p < .001\). This supports a factor (or component) analytic approach for investigating the data.
9.5.1.1.3 Is there multicollinearity or singularity in my data?
The determinant of the correlation matrix should be greater than 0.00001 (that would be 4 zeros before the 1). If it is smaller than 0.00001 then we may have an issue with multicollinearity (i.e., variables that are too highly correlated) or singularity (variables that are perfectly correlated).
The determinant function comes from base R. It is easiest to compute when the correlation matrix is the object. However, it is also possible to specify the command to work with the raw data.
[1] 0.007499909With a value of 0.0075, our determinant is greater than the 0.00001 requirement. If it were not, then we could identify problematic variables (i.e., those correlating too highly with others and those not correlating sufficiently with others) and re-run the diagnostic statistics.
9.5.1.2 APA Style Summary So Far
Data screening were conducted to determine the suitability of the data for principal axis factoring. The Kaiser-Meyer-Olkin measure of sampling adequacy (KMO; Kaiser, 1970) represents the ratio of the squared correlation between variables to the squared partial correlation between variables. KMO ranges from 0.00 to 1.00; values closer to 1.00 indicate that the patterns of correlations are relatively compact, and that factor analysis should yield distinct and reliable factors (Field, 2012). In our dataset, the KMO value was .85, indicating acceptable sampling adequacy. The Barlett’s Test of Sphericity examines whether the population correlation matrix resembles an identity matrix (Field, 2012). When the p value for the Bartlett’s test is < .05, we are fairly certain we have clusters of correlated variables. In our dataset, \(\chi^{2}(300)=1217.508, p < .001\), indicating the correlations between items are sufficiently large enough for principal axis factoring. The determinant of the correlation matrix alerts us to any issues of multicollinearity or singularity and should be larger than 0.00001. Our determinant was 0.0075, supporting the suitability of our data for analysis.
Note: If this looks familiar, it is! The same diagnostics are used in PAF and PCA.
9.5.2 Principal Axis Factoring (PAF)
Here’s a snip of our location in the PAF workflow.

We can use the fa() function, specifying fm = “pa” from the psych package with raw or matrix data.
One difference from PCA is that factor analysis will not (cannot) calculate as many factors as there are items. This means that we should select a reasonable number, like 20 (since there are 25 items). However, I received a number of errors/warnings and 13 is the first number that would run. I also received the warning, “maximum iteration exceeded.” Therefore, I increased “max.iter” to 100.
Our goal is to begin to get an idea of the cumulative variance explained, and number of factors to extract. If we think there are four factors, we simply need to specify more than four factors on the nfactors = ## command. As long as that number is less than the total number of items, it does not matter what that number is.
# grmsPAF1 <- psych::fa(GRMSr, nfactors=10, fm = 'pa', max.iter =
# 100, rotate='none')# using the matrix data and specifying the # of
# factors.
grmsPAF1 <- psych::fa(dfGRMS, nfactors = 13, fm = "pa", max.iter = 100,
rotate = "none") # using raw data and specifying the max number of factors
# I received the warning 'maximum iteration exceeded'. It gave
# output, but it's best if we don't get that warning, so I increased
# it to 100.
grmsPAF1 #this object holds a great deal of information Factor Analysis using method = pa
Call: psych::fa(r = dfGRMS, nfactors = 13, rotate = "none", max.iter = 100,
fm = "pa")
Standardized loadings (pattern matrix) based upon correlation matrix
PA1 PA2 PA3 PA4 PA5 PA6 PA7 PA8 PA9 PA10 PA11 PA12
Obj1 0.49 -0.20 -0.01 0.13 -0.01 0.11 -0.17 -0.16 0.01 -0.09 0.21 0.04
Obj2 0.51 -0.19 -0.03 0.13 0.07 -0.02 -0.04 0.00 0.06 -0.08 0.09 -0.01
Obj3 0.45 -0.17 -0.01 0.05 0.03 0.09 0.00 0.12 -0.04 -0.04 0.14 0.10
Obj4 0.49 -0.25 -0.11 0.03 -0.06 0.04 0.04 0.03 -0.09 0.18 -0.09 0.19
Obj5 0.54 -0.46 0.06 -0.50 -0.46 0.01 -0.09 0.08 0.04 -0.01 -0.06 -0.07
Obj6 0.38 -0.15 0.00 0.39 -0.08 0.07 -0.06 0.36 -0.08 0.02 0.09 -0.18
Obj7 0.51 -0.04 -0.04 0.16 0.06 0.03 -0.02 -0.22 0.05 0.02 -0.05 -0.12
Obj8 0.46 -0.29 -0.17 -0.02 0.15 0.05 -0.08 -0.25 -0.03 0.24 0.09 -0.11
Obj9 0.40 -0.30 0.16 0.09 0.06 -0.44 0.35 0.01 -0.27 -0.09 -0.03 -0.04
Obj10 0.39 -0.23 -0.04 0.21 0.00 -0.01 0.12 -0.15 0.33 -0.04 -0.19 0.20
Marg1 0.56 0.33 -0.24 -0.12 0.11 -0.12 -0.15 -0.06 -0.07 0.05 -0.11 -0.07
Marg2 0.55 0.30 0.03 -0.07 0.02 -0.14 -0.21 0.06 0.00 -0.07 0.05 0.15
Marg3 0.48 0.18 -0.09 -0.17 0.08 -0.19 0.11 0.01 0.12 -0.17 -0.01 0.00
Marg4 0.51 0.21 -0.47 -0.20 0.03 0.32 0.38 0.00 -0.08 -0.08 0.14 -0.02
Marg5 0.52 0.15 -0.09 -0.10 0.04 -0.10 -0.13 0.14 -0.13 0.03 -0.08 0.09
Marg6 0.51 0.02 -0.13 0.08 0.09 0.00 -0.01 0.12 0.15 0.08 -0.24 -0.16
Marg7 0.37 0.17 -0.10 0.05 0.08 -0.22 -0.12 0.12 0.06 0.13 0.12 0.08
Str1 0.40 0.02 0.34 -0.14 0.18 0.01 -0.07 -0.14 0.02 -0.18 0.07 -0.14
Str2 0.36 0.01 0.17 0.07 0.07 0.14 0.17 0.04 -0.01 -0.14 -0.05 0.11
Str3 0.30 0.10 0.38 -0.02 0.13 0.13 -0.01 -0.03 -0.03 -0.05 -0.17 -0.07
Str4 0.27 -0.03 0.36 -0.13 0.28 0.32 0.00 0.16 -0.10 0.16 -0.09 0.08
Str5 0.30 0.07 0.27 -0.02 -0.07 0.01 -0.11 0.04 0.13 -0.06 0.16 0.04
Ang1 0.34 0.32 0.38 -0.03 -0.17 -0.10 0.28 -0.11 0.09 0.34 0.16 -0.01
Ang2 0.30 0.28 0.00 0.15 -0.24 0.08 0.12 0.16 0.22 -0.02 -0.03 -0.08
Ang3 0.38 0.32 0.06 0.25 -0.39 0.12 -0.10 -0.24 -0.29 -0.07 -0.12 0.03
PA13 h2 u2 com
Obj1 -0.05 0.42 0.5768 2.8
Obj2 -0.15 0.36 0.6397 1.9
Obj3 -0.07 0.30 0.7008 2.1
Obj4 0.11 0.43 0.5749 2.7
Obj5 0.00 1.00 0.0031 4.1
Obj6 0.05 0.51 0.4897 4.2
Obj7 0.12 0.38 0.6219 1.9
Obj8 -0.07 0.50 0.4962 4.2
Obj9 -0.01 0.69 0.3115 5.1
Obj10 0.05 0.48 0.5243 5.2
Marg1 -0.07 0.58 0.4213 2.9
Marg2 0.01 0.50 0.5037 2.4
Marg3 -0.20 0.44 0.5594 3.2
Marg4 0.12 0.86 0.1379 4.9
Marg5 0.12 0.41 0.5908 2.2
Marg6 -0.03 0.42 0.5816 2.5
Marg7 0.10 0.31 0.6869 4.2
Str1 0.11 0.43 0.5733 4.2
Str2 -0.02 0.25 0.7472 3.3
Str3 0.15 0.34 0.6630 3.7
Str4 -0.17 0.51 0.4923 6.2
Str5 0.10 0.25 0.7537 4.0
Ang1 -0.02 0.64 0.3585 6.3
Ang2 -0.07 0.35 0.6509 5.8
Ang3 -0.09 0.66 0.3388 6.2
PA1 PA2 PA3 PA4 PA5 PA6 PA7 PA8 PA9 PA10 PA11
SS loadings 4.86 1.25 1.04 0.76 0.68 0.62 0.58 0.51 0.45 0.39 0.36
Proportion Var 0.19 0.05 0.04 0.03 0.03 0.02 0.02 0.02 0.02 0.02 0.01
Cumulative Var 0.19 0.24 0.29 0.32 0.34 0.37 0.39 0.41 0.43 0.45 0.46
Proportion Explained 0.40 0.10 0.09 0.06 0.06 0.05 0.05 0.04 0.04 0.03 0.03
Cumulative Proportion 0.40 0.51 0.60 0.66 0.72 0.77 0.82 0.86 0.89 0.93 0.96
PA12 PA13
SS loadings 0.27 0.24
Proportion Var 0.01 0.01
Cumulative Var 0.47 0.48
Proportion Explained 0.02 0.02
Cumulative Proportion 0.98 1.00
Mean item complexity = 3.8
Test of the hypothesis that 13 factors are sufficient.
df null model = 300 with the objective function = 4.89 with Chi Square = 1217.51
df of the model are 53 and the objective function was 0.1
The root mean square of the residuals (RMSR) is 0.01
The df corrected root mean square of the residuals is 0.03
The harmonic n.obs is 259 with the empirical chi square 17.64 with prob < 1
The total n.obs was 259 with Likelihood Chi Square = 24.56 with prob < 1
Tucker Lewis Index of factoring reliability = 1.184
RMSEA index = 0 and the 90 % confidence intervals are 0 0
BIC = -269.95
Fit based upon off diagonal values = 1
Measures of factor score adequacy
PA1 PA2 PA3 PA4 PA5 PA6
Correlation of (regression) scores with factors 0.96 0.89 0.85 0.87 0.85 0.79
Multiple R square of scores with factors 0.92 0.79 0.72 0.75 0.72 0.62
Minimum correlation of possible factor scores 0.83 0.58 0.44 0.51 0.44 0.25
PA7 PA8 PA9 PA10 PA11
Correlation of (regression) scores with factors 0.80 0.71 0.71 0.67 0.64
Multiple R square of scores with factors 0.64 0.50 0.50 0.45 0.42
Minimum correlation of possible factor scores 0.28 0.01 0.00 -0.09 -0.17
PA12 PA13
Correlation of (regression) scores with factors 0.58 0.56
Multiple R square of scores with factors 0.34 0.31
Minimum correlation of possible factor scores -0.33 -0.38The total variance for a particular variable will have two factors: some variance will be shared with other variables (common variance) and some variance will be specific to that measure (unique variance). Random variance is also specific to one item, but not reliably so. We can examine this most easily by examining the matrix (second screen).
The columns PA1 thru PA10 are the (uninteresting at this point) unrotated loadings. These are the loading from each factor to each variable. PA stands for “principal axis.”
Scrolling to the far right we are interested in:
Communalities are represented as \(h^2\). These are the proportions of common variance present in the variables. A variable that has no specific (or random) variance would have a communality of 1.0. If a variable shares none of its variance with any other variable, its communality would be 0.0. As a point of comparison, in PCA these started as 1.0 because we extracted the same number of components as items. In PAF, because we must extract fewer factors than items, these will have unique values.
**Uniquenesses* are represented as \(u2\). These are the amount of unique variance for each variable. They are calculated as \(1 - h^2\) (or 1 minus the communality).
The final column, com represents item complexity. This is an indication of how well an item reflects a single construct. If it is 1.0 then the item loads only on one factor, if it is 2.0, it loads evenly on two factors, and so forth. For now, we can ignore this. I mostly wanted to reassure you that “com” is not “communality” – h2 is communality.
Let’s switch to the first screen of output.
Eigenvalues are displayed in the row called, SS loadings (i.e., the sum of squared loadings). They represent the variance explained by the particular linear factor. PA1 explains 4.86 units of variance (out of a possible 25; the # of potential factors). As a proportion, this is 4.86/25 = 0.1944 (reported in the Proportion Var row). We inspect the eigenvalues to see how many are > 1.0 (Kaiser’s eigenvalue > 1 criteria criteria). We see there are three that meet Kaiser’s critera and four that meet Joliffe’s criteria (eigenvalues > .70).
[1] 0.1944Cumulative Var is helpful to determine how many factors we’d like to retain to balance parsimony (few as possible) with the amount of variance we want to explain. Directly related to the eigenvalues, we can see how including each additional factor accounts for a greater proportion of variance.
Scree plots can help us visualize the relationship between the eigenvalues. A rule of thumb is to select the number of factors that is associated with the number of dots before the flattening of the curve. Eigenvalues are stored in the grmsPAF1 object’s variable, “values”. We can see all the values captured by this object with the names() function:
[1] "residual" "dof" "chi"
[4] "nh" "rms" "EPVAL"
[7] "crms" "EBIC" "ESABIC"
[10] "fit" "fit.off" "sd"
[13] "factors" "complexity" "n.obs"
[16] "objective" "criteria" "STATISTIC"
[19] "PVAL" "Call" "null.model"
[22] "null.dof" "null.chisq" "TLI"
[25] "F0" "RMSEA" "BIC"
[28] "SABIC" "r.scores" "R2"
[31] "valid" "score.cor" "weights"
[34] "rotation" "hyperplane" "communality"
[37] "communalities" "uniquenesses" "values"
[40] "e.values" "loadings" "model"
[43] "fm" "Structure" "communality.iterations"
[46] "method" "scores" "R2.scores"
[49] "r" "np.obs" "fn"
[52] "Vaccounted" plot(grmsPAF1$values, type = "b") #type = 'b' gives us 'both' lines and points; type = 'l' gives lines and is relatively worthless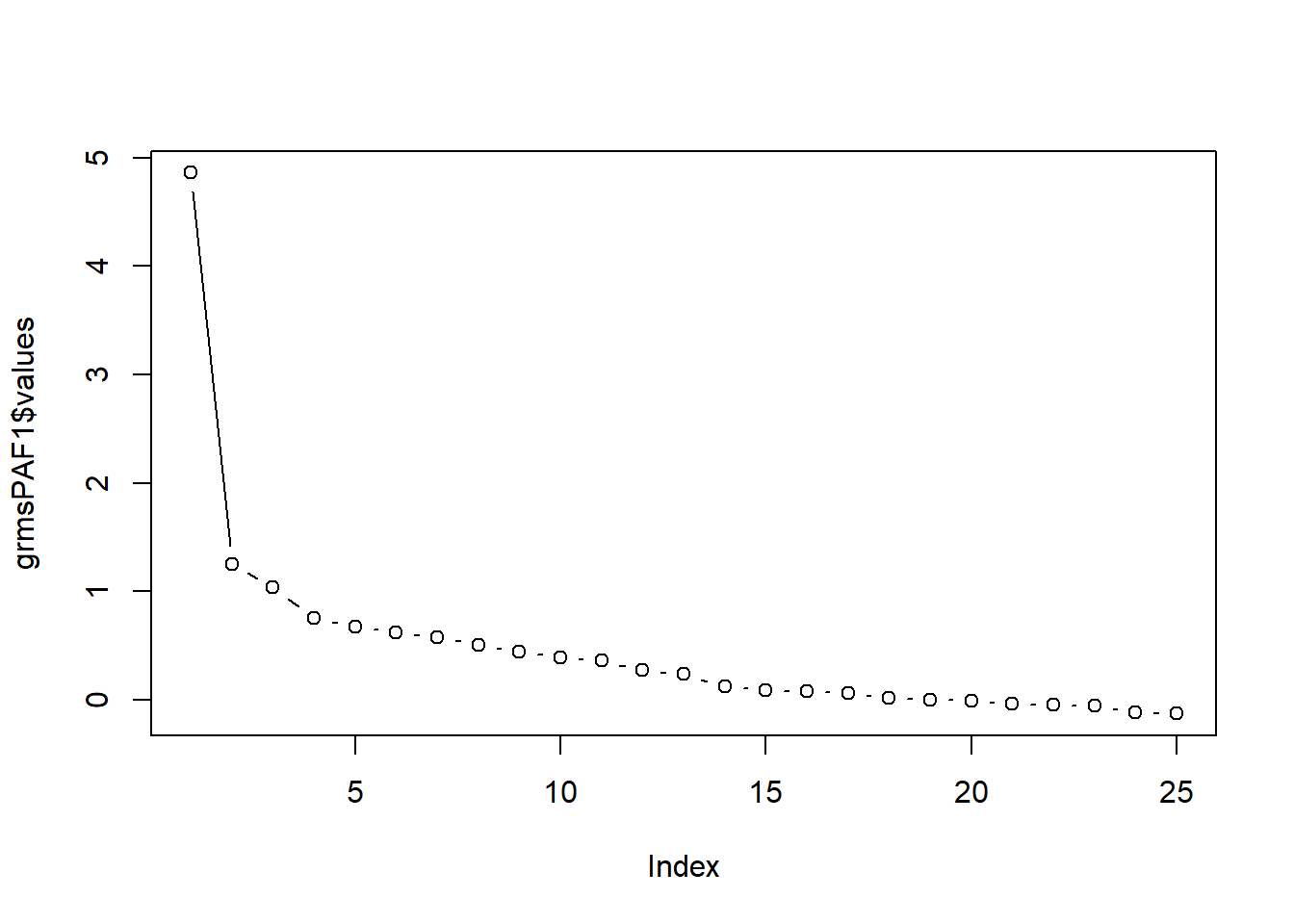
We look for the point of inflexion. That is, where the baseline levels out into a plateau. I can see inflections after 1, 2, 3, and 4.
9.5.2.1 Specifying the number of factors
Here’s a snip of our location in the PAF workflow.

Having determined the number of factors, we must rerun the analysis with this specification. Especially when researchers may not have a clear theoretical structure that guides the process, researchers may do this iteratively with varying numbers of factors. Lewis and Neville (J. A. Lewis & Neville, 2015) examined solutions with 2, 3, 4, and 5 factors (they conducted a parallel factor analysis; in contrast this lesson demonstrates principal axis factoring).
# grmsPAF2 <- psych::fa(GRMSr, nfactors=4, fm = 'pa', rotate='none')
grmsPAF2 <- psych::fa(dfGRMS, nfactors = 4, fm = "pa", rotate = "none") #can copy prior script, but change nfactors and object name
grmsPAF2Factor Analysis using method = pa
Call: psych::fa(r = dfGRMS, nfactors = 4, rotate = "none", fm = "pa")
Standardized loadings (pattern matrix) based upon correlation matrix
PA1 PA2 PA3 PA4 h2 u2 com
Obj1 0.48 -0.24 0.02 0.02 0.29 0.71 1.5
Obj2 0.52 -0.22 -0.02 0.06 0.32 0.68 1.4
Obj3 0.45 -0.20 0.02 0.05 0.25 0.75 1.4
Obj4 0.49 -0.27 -0.12 0.03 0.33 0.67 1.7
Obj5 0.47 -0.23 0.03 -0.05 0.28 0.72 1.5
Obj6 0.37 -0.15 0.00 0.26 0.22 0.78 2.2
Obj7 0.51 -0.09 -0.02 0.02 0.27 0.73 1.1
Obj8 0.45 -0.31 -0.16 -0.16 0.35 0.65 2.4
Obj9 0.37 -0.21 0.08 -0.02 0.19 0.81 1.7
Obj10 0.38 -0.23 -0.02 0.14 0.22 0.78 2.0
Marg1 0.58 0.36 -0.31 -0.23 0.62 0.38 2.6
Marg2 0.55 0.31 0.00 -0.09 0.41 0.59 1.6
Marg3 0.48 0.19 -0.09 -0.09 0.28 0.72 1.5
Marg4 0.46 0.11 -0.24 0.01 0.28 0.72 1.6
Marg5 0.53 0.16 -0.11 -0.11 0.33 0.67 1.4
Marg6 0.50 0.01 -0.12 0.06 0.27 0.73 1.2
Marg7 0.37 0.16 -0.13 -0.03 0.18 0.82 1.6
Str1 0.40 0.04 0.38 -0.24 0.36 0.64 2.6
Str2 0.36 -0.01 0.21 0.08 0.18 0.82 1.7
Str3 0.30 0.10 0.41 -0.08 0.28 0.72 2.1
Str4 0.26 -0.03 0.29 -0.11 0.17 0.83 2.3
Str5 0.31 0.09 0.27 0.04 0.18 0.82 2.2
Ang1 0.32 0.24 0.24 0.08 0.22 0.78 3.0
Ang2 0.31 0.31 0.01 0.49 0.43 0.57 2.5
Ang3 0.35 0.21 0.03 0.17 0.19 0.81 2.1
PA1 PA2 PA3 PA4
SS loadings 4.67 1.03 0.83 0.57
Proportion Var 0.19 0.04 0.03 0.02
Cumulative Var 0.19 0.23 0.26 0.28
Proportion Explained 0.66 0.15 0.12 0.08
Cumulative Proportion 0.66 0.80 0.92 1.00
Mean item complexity = 1.9
Test of the hypothesis that 4 factors are sufficient.
df null model = 300 with the objective function = 4.89 with Chi Square = 1217.51
df of the model are 206 and the objective function was 0.77
The root mean square of the residuals (RMSR) is 0.04
The df corrected root mean square of the residuals is 0.04
The harmonic n.obs is 259 with the empirical chi square 202.41 with prob < 0.56
The total n.obs was 259 with Likelihood Chi Square = 189.19 with prob < 0.79
Tucker Lewis Index of factoring reliability = 1.027
RMSEA index = 0 and the 90 % confidence intervals are 0 0.018
BIC = -955.52
Fit based upon off diagonal values = 0.97
Measures of factor score adequacy
PA1 PA2 PA3 PA4
Correlation of (regression) scores with factors 0.93 0.79 0.74 0.70
Multiple R square of scores with factors 0.87 0.62 0.55 0.48
Minimum correlation of possible factor scores 0.75 0.24 0.11 -0.03Our eigenvalues/SS loadings wiggle around a bit from the initial run. With four factors, we now, cumulatively, explain 28% of the variance.
Communality is the proportion of common variance within a variable. Changing from 13 to 4 factors changed these values (\(h2\)) as well as their associated uniquenesses (\(u2\)), which are calculated as “1.0 minus the communality.”
Now we see that 29% of the variance associated with Obj1 is common/shared (the \(h2\) value).
As a reminder of what we are doing, recall that we are looking for a more parsimonious explanation than 25 items on the GRMS. By respecifying a smaller number of factors, we lose some information. That is, the retained factors (now 4) cannot explain all of the variance present in the data (as we saw, it explains about 28%, cumulatively). The amount of variance explained in each variable is represented by the communalities after extraction.
We can also inspect the communalities through the lens of Kaiser’s criterion (the eigenvalue > 1 criteria) to see if we think that four was a good number of factors to extract.
Kaiser’s criterion is believed to be accurate:
- when there are fewer than 30 variables (we had 25) and, after extraction, the communalities are greater than .70
- looking at our data, none of the communalities is > .70, so, this does not support extracting four factors
- When the sample size is greater than 250 (ours was 259) and the average communality is > .60
- calculated below, ours was .28.
Using the names() function again, we see that “communality” is available for manipulation.
[1] "residual" "dof" "chi"
[4] "nh" "rms" "EPVAL"
[7] "crms" "EBIC" "ESABIC"
[10] "fit" "fit.off" "sd"
[13] "factors" "complexity" "n.obs"
[16] "objective" "criteria" "STATISTIC"
[19] "PVAL" "Call" "null.model"
[22] "null.dof" "null.chisq" "TLI"
[25] "F0" "RMSEA" "BIC"
[28] "SABIC" "r.scores" "R2"
[31] "valid" "score.cor" "weights"
[34] "rotation" "hyperplane" "communality"
[37] "communalities" "uniquenesses" "values"
[40] "e.values" "loadings" "model"
[43] "fm" "Structure" "communality.iterations"
[46] "method" "scores" "R2.scores"
[49] "r" "np.obs" "fn"
[52] "Vaccounted" We can use this value to calculate their mean.
[1] 0.2840516We see that our average communality is 0.28. These two criteria suggest that we may not have the best solution. That said (in our defense):
- We used the scree plot as a guide, and it was very clear.
- We have an adequate sample size and that was supported with the KMO.
- Are the number of factors consistent with theory? We have not yet inspected the factor loadings. This will provide us with more information.
We could do several things:
- rerun with a different number of factors (recall Lewis and Neville (2015) ran models with 2, 3, 4, and 5 factors)
- conduct more diagnostics tests
- reproduced correlation matrix
- the difference between the reproduced correlation matrix and the correlation matrix from the data
The factor.model() function in psych produces the reproduced correlation matrix by using the loadings in our extracted object. Conceptually, this matrix is the correlations that should be produced if we did not have the raw data, but we only had the factor loadings.
The questions, though, is: How close did we get? How different is the reproduced correlation matrix from GRMSmatrix – the \(R\)-matrix produced from our raw data.
Obj1 Obj2 Obj3 Obj4 Obj5 Obj6 Obj7 Obj8 Obj9 Obj10 Marg1 Marg2
Obj1 0.293 0.304 0.270 0.300 0.284 0.219 0.270 0.287 0.229 0.242 0.187 0.193
Obj2 0.304 0.319 0.282 0.317 0.291 0.239 0.286 0.294 0.232 0.256 0.215 0.212
Obj3 0.270 0.282 0.250 0.277 0.260 0.209 0.252 0.258 0.209 0.225 0.178 0.185
Obj4 0.300 0.317 0.277 0.326 0.288 0.229 0.279 0.317 0.225 0.255 0.219 0.186
Obj5 0.284 0.291 0.260 0.288 0.280 0.196 0.261 0.287 0.226 0.225 0.193 0.194
Obj6 0.219 0.239 0.209 0.229 0.196 0.225 0.207 0.169 0.161 0.210 0.097 0.131
Obj7 0.270 0.286 0.252 0.279 0.261 0.207 0.273 0.260 0.205 0.218 0.271 0.256
Obj8 0.287 0.294 0.258 0.317 0.287 0.169 0.260 0.353 0.221 0.223 0.242 0.170
Obj9 0.229 0.232 0.209 0.225 0.226 0.161 0.205 0.221 0.186 0.183 0.118 0.140
Obj10 0.242 0.256 0.225 0.255 0.225 0.210 0.218 0.223 0.183 0.217 0.113 0.126
Marg1 0.187 0.215 0.178 0.219 0.193 0.097 0.271 0.242 0.118 0.113 0.619 0.455
Marg2 0.193 0.212 0.185 0.186 0.194 0.131 0.256 0.170 0.140 0.126 0.455 0.411
Marg3 0.182 0.201 0.173 0.191 0.182 0.121 0.228 0.187 0.129 0.126 0.393 0.329
Marg4 0.195 0.221 0.186 0.226 0.185 0.155 0.234 0.212 0.127 0.158 0.378 0.287
Marg5 0.213 0.233 0.201 0.225 0.213 0.140 0.257 0.225 0.153 0.151 0.424 0.350
Marg6 0.239 0.263 0.227 0.259 0.227 0.197 0.261 0.233 0.169 0.199 0.322 0.276
Marg7 0.140 0.159 0.134 0.154 0.136 0.105 0.180 0.145 0.093 0.104 0.320 0.257
Str1 0.188 0.177 0.171 0.136 0.206 0.082 0.191 0.148 0.177 0.103 0.187 0.258
Str2 0.184 0.190 0.174 0.160 0.178 0.155 0.184 0.122 0.151 0.147 0.124 0.189
Str3 0.128 0.119 0.120 0.072 0.137 0.075 0.136 0.053 0.126 0.071 0.105 0.207
Str4 0.135 0.126 0.122 0.097 0.144 0.070 0.126 0.097 0.128 0.082 0.075 0.145
Str5 0.134 0.136 0.128 0.097 0.132 0.111 0.145 0.061 0.116 0.097 0.115 0.193
Ang1 0.101 0.110 0.103 0.066 0.098 0.101 0.138 0.016 0.083 0.070 0.176 0.242
Ang2 0.087 0.123 0.102 0.085 0.052 0.193 0.143 -0.037 0.038 0.114 0.177 0.223
Ang3 0.125 0.146 0.126 0.120 0.111 0.141 0.165 0.063 0.084 0.109 0.231 0.243
Marg3 Marg4 Marg5 Marg6 Marg7 Str1 Str2 Str3 Str4 Str5 Ang1 Ang2
Obj1 0.182 0.195 0.213 0.239 0.140 0.188 0.184 0.128 0.135 0.134 0.101 0.087
Obj2 0.201 0.221 0.233 0.263 0.159 0.177 0.190 0.119 0.126 0.136 0.110 0.123
Obj3 0.173 0.186 0.201 0.227 0.134 0.171 0.174 0.120 0.122 0.128 0.103 0.102
Obj4 0.191 0.226 0.225 0.259 0.154 0.136 0.160 0.072 0.097 0.097 0.066 0.085
Obj5 0.182 0.185 0.213 0.227 0.136 0.206 0.178 0.137 0.144 0.132 0.098 0.052
Obj6 0.121 0.155 0.140 0.197 0.105 0.082 0.155 0.075 0.070 0.111 0.101 0.193
Obj7 0.228 0.234 0.257 0.261 0.180 0.191 0.184 0.136 0.126 0.145 0.138 0.143
Obj8 0.187 0.212 0.225 0.233 0.145 0.148 0.122 0.053 0.097 0.061 0.016 -0.037
Obj9 0.129 0.127 0.153 0.169 0.093 0.177 0.151 0.126 0.128 0.116 0.083 0.038
Obj10 0.126 0.158 0.151 0.199 0.104 0.103 0.147 0.071 0.082 0.097 0.070 0.114
Marg1 0.393 0.378 0.424 0.322 0.320 0.187 0.124 0.105 0.075 0.115 0.176 0.177
Marg2 0.329 0.287 0.350 0.276 0.257 0.258 0.189 0.207 0.145 0.193 0.242 0.223
Marg3 0.277 0.260 0.300 0.247 0.220 0.185 0.143 0.132 0.100 0.133 0.165 0.161
Marg4 0.260 0.281 0.286 0.264 0.219 0.098 0.117 0.052 0.045 0.087 0.116 0.182
Marg5 0.300 0.286 0.326 0.274 0.238 0.201 0.156 0.137 0.110 0.140 0.168 0.160
Marg6 0.247 0.264 0.274 0.271 0.203 0.142 0.160 0.097 0.085 0.123 0.136 0.189
Marg7 0.220 0.219 0.238 0.203 0.181 0.113 0.103 0.077 0.056 0.091 0.122 0.151
Str1 0.185 0.098 0.201 0.142 0.113 0.363 0.206 0.300 0.241 0.221 0.209 0.025
Str2 0.143 0.117 0.156 0.160 0.103 0.206 0.179 0.186 0.146 0.170 0.167 0.146
Str3 0.132 0.052 0.137 0.097 0.077 0.300 0.186 0.276 0.205 0.210 0.212 0.087
Str4 0.100 0.045 0.110 0.085 0.056 0.241 0.146 0.205 0.167 0.152 0.136 0.018
Str5 0.133 0.087 0.140 0.123 0.091 0.221 0.170 0.210 0.152 0.178 0.187 0.145
Ang1 0.165 0.116 0.168 0.136 0.122 0.209 0.167 0.212 0.136 0.187 0.223 0.215
Ang2 0.161 0.182 0.160 0.189 0.151 0.025 0.146 0.087 0.018 0.145 0.215 0.431
Ang3 0.187 0.180 0.196 0.186 0.155 0.120 0.142 0.123 0.073 0.140 0.181 0.256
Ang3
Obj1 0.125
Obj2 0.146
Obj3 0.126
Obj4 0.120
Obj5 0.111
Obj6 0.141
Obj7 0.165
Obj8 0.063
Obj9 0.084
Obj10 0.109
Marg1 0.231
Marg2 0.243
Marg3 0.187
Marg4 0.180
Marg5 0.196
Marg6 0.186
Marg7 0.155
Str1 0.120
Str2 0.142
Str3 0.123
Str4 0.073
Str5 0.140
Ang1 0.181
Ang2 0.256
Ang3 0.195We’re not really interested in this matrix. We just need it to compare it to the GRMSmatrix to produce the residuals. We do that next.
Residuals are the difference between the reproduced (i.e., those created from our factor loadings) and \(R\)-matrix produced by the raw data.
If we look at the \(r_{_{Obj1Obj2}}\) in our original correlation matrix (theoretically from the raw data [although we simulated data]), the value is 0.35. The reproduced correlation for this pair is 0.304. The difference is 0.046. The residuals table below shows 0.051 (rounding error).
[1] 0.046By using the factor.residuals() function we can calculate the residuals. Here we will see this difference calculated for us, for all the elements in the matrix.
Obj1 Obj2 Obj3 Obj4 Obj5 Obj6 Obj7 Obj8 Obj9 Obj10
Obj1 0.707 0.051 -0.020 -0.030 -0.002 0.031 0.011 0.059 -0.076 -0.001
Obj2 0.051 0.681 0.030 -0.069 -0.023 -0.005 0.026 -0.012 0.030 -0.011
Obj3 -0.020 0.030 0.750 -0.036 0.023 0.070 -0.051 -0.009 0.000 -0.010
Obj4 -0.030 -0.069 -0.036 0.674 0.099 0.003 0.006 -0.020 0.031 0.024
Obj5 -0.002 -0.023 0.023 0.099 0.720 -0.043 -0.084 0.004 0.026 -0.021
Obj6 0.031 -0.005 0.070 0.003 -0.043 0.775 -0.008 -0.028 0.046 -0.089
Obj7 0.011 0.026 -0.051 0.006 -0.084 -0.008 0.727 0.047 -0.012 0.065
Obj8 0.059 -0.012 -0.009 -0.020 0.004 -0.028 0.047 0.647 -0.028 0.007
Obj9 -0.076 0.030 0.000 0.031 0.026 0.046 -0.012 -0.028 0.814 0.016
Obj10 -0.001 -0.011 -0.010 0.024 -0.021 -0.089 0.065 0.007 0.016 0.783
Marg1 -0.002 0.001 -0.009 0.001 -0.027 0.005 0.025 0.025 -0.017 -0.019
Marg2 0.053 -0.005 0.045 -0.009 0.003 0.007 -0.042 -0.034 -0.023 -0.003
Marg3 -0.013 0.045 0.001 -0.054 0.044 -0.069 -0.030 -0.048 0.086 0.039
Marg4 -0.007 -0.041 0.056 0.030 0.013 -0.054 0.017 0.026 -0.060 -0.036
Marg5 -0.042 -0.014 0.011 0.043 0.039 0.021 -0.026 -0.038 0.036 -0.042
Marg6 -0.061 0.006 -0.067 -0.031 -0.002 0.066 0.024 0.027 -0.019 0.057
Marg7 -0.010 0.032 0.008 0.039 -0.079 0.069 -0.024 -0.004 0.011 0.005
Str1 0.027 0.008 -0.029 -0.074 0.025 -0.016 0.055 0.018 0.014 -0.002
Str2 0.004 -0.006 0.015 0.030 -0.061 -0.003 -0.049 -0.059 0.032 0.040
Str3 -0.030 -0.031 -0.029 0.008 -0.028 0.020 0.052 -0.007 -0.010 0.028
Str4 -0.041 0.015 0.061 0.054 -0.023 0.013 -0.056 0.031 -0.075 -0.060
Str5 0.064 0.009 0.024 -0.017 0.058 0.002 0.003 -0.024 -0.051 -0.006
Ang1 -0.038 -0.042 -0.030 0.026 0.019 -0.061 0.013 0.057 0.086 -0.008
Ang2 -0.028 0.022 -0.019 -0.025 0.035 0.003 -0.012 0.010 -0.042 0.024
Ang3 0.081 -0.019 -0.015 0.020 -0.006 0.015 0.061 0.002 -0.022 -0.025
Marg1 Marg2 Marg3 Marg4 Marg5 Marg6 Marg7 Str1 Str2 Str3
Obj1 -0.002 0.053 -0.013 -0.007 -0.042 -0.061 -0.010 0.027 0.004 -0.030
Obj2 0.001 -0.005 0.045 -0.041 -0.014 0.006 0.032 0.008 -0.006 -0.031
Obj3 -0.009 0.045 0.001 0.056 0.011 -0.067 0.008 -0.029 0.015 -0.029
Obj4 0.001 -0.009 -0.054 0.030 0.043 -0.031 0.039 -0.074 0.030 0.008
Obj5 -0.027 0.003 0.044 0.013 0.039 -0.002 -0.079 0.025 -0.061 -0.028
Obj6 0.005 0.007 -0.069 -0.054 0.021 0.066 0.069 -0.016 -0.003 0.020
Obj7 0.025 -0.042 -0.030 0.017 -0.026 0.024 -0.024 0.055 -0.049 0.052
Obj8 0.025 -0.034 -0.048 0.026 -0.038 0.027 -0.004 0.018 -0.059 -0.007
Obj9 -0.017 -0.023 0.086 -0.060 0.036 -0.019 0.011 0.014 0.032 -0.010
Obj10 -0.019 -0.003 0.039 -0.036 -0.042 0.057 0.005 -0.002 0.040 0.028
Marg1 0.381 -0.030 0.013 -0.002 -0.017 0.026 -0.011 0.003 -0.004 0.026
Marg2 -0.030 0.589 0.019 -0.057 0.053 -0.009 0.069 -0.005 -0.007 -0.027
Marg3 0.013 0.019 0.723 0.063 -0.049 0.007 -0.016 0.018 0.030 -0.036
Marg4 -0.002 -0.057 0.063 0.719 0.013 -0.006 -0.055 0.001 0.094 -0.004
Marg5 -0.017 0.053 -0.049 0.013 0.674 0.016 0.044 -0.043 -0.023 0.020
Marg6 0.026 -0.009 0.007 -0.006 0.016 0.729 -0.005 -0.012 0.024 0.050
Marg7 -0.011 0.069 -0.016 -0.055 0.044 -0.005 0.819 0.027 -0.051 -0.036
Str1 0.003 -0.005 0.018 0.001 -0.043 -0.012 0.027 0.637 0.009 0.001
Str2 -0.004 -0.007 0.030 0.094 -0.023 0.024 -0.051 0.009 0.821 0.012
Str3 0.026 -0.027 -0.036 -0.004 0.020 0.050 -0.036 0.001 0.012 0.724
Str4 0.009 -0.027 -0.021 0.018 0.031 0.048 -0.039 -0.015 0.057 0.063
Str5 -0.015 0.035 -0.010 -0.054 0.037 -0.040 0.032 0.010 -0.048 -0.029
Ang1 -0.014 -0.010 0.016 0.002 -0.053 -0.031 0.049 -0.028 -0.007 -0.013
Ang2 -0.007 -0.038 0.031 0.041 -0.018 0.024 -0.018 0.025 -0.025 -0.012
Ang3 0.048 0.036 -0.077 -0.007 0.012 -0.069 -0.069 -0.018 0.013 0.024
Str4 Str5 Ang1 Ang2 Ang3
Obj1 -0.041 0.064 -0.038 -0.028 0.081
Obj2 0.015 0.009 -0.042 0.022 -0.019
Obj3 0.061 0.024 -0.030 -0.019 -0.015
Obj4 0.054 -0.017 0.026 -0.025 0.020
Obj5 -0.023 0.058 0.019 0.035 -0.006
Obj6 0.013 0.002 -0.061 0.003 0.015
Obj7 -0.056 0.003 0.013 -0.012 0.061
Obj8 0.031 -0.024 0.057 0.010 0.002
Obj9 -0.075 -0.051 0.086 -0.042 -0.022
Obj10 -0.060 -0.006 -0.008 0.024 -0.025
Marg1 0.009 -0.015 -0.014 -0.007 0.048
Marg2 -0.027 0.035 -0.010 -0.038 0.036
Marg3 -0.021 -0.010 0.016 0.031 -0.077
Marg4 0.018 -0.054 0.002 0.041 -0.007
Marg5 0.031 0.037 -0.053 -0.018 0.012
Marg6 0.048 -0.040 -0.031 0.024 -0.069
Marg7 -0.039 0.032 0.049 -0.018 -0.069
Str1 -0.015 0.010 -0.028 0.025 -0.018
Str2 0.057 -0.048 -0.007 -0.025 0.013
Str3 0.063 -0.029 -0.013 -0.012 0.024
Str4 0.833 -0.034 0.017 0.013 -0.051
Str5 -0.034 0.822 0.036 0.009 -0.034
Ang1 0.017 0.036 0.777 0.025 0.051
Ang2 0.013 0.009 0.025 0.569 -0.006
Ang3 -0.051 -0.034 0.051 -0.006 0.805There are several strategies to evaluate this matrix.
- Compare the size of the residuals to the original correlations.
- The worst possible model would occur if we extracted no factors, and the residuals are the size of the original correlations.
- If the correlations were small to start with, we expect small residuals.
- If the correlations were large to start with, the residuals will be relatively larger (this is not terribly problematic).
- Comparing residuals requires squaring them first (because residuals can be both positive and negative)
- The sum of the squared residuals divided by the sum of the squared correlations is an estimate of model fit.
- Subtracting this from 1.0 means that it ranges from 0 to 1.
- Values > .95 are an indication of good fit.
- Subtracting this from 1.0 means that it ranges from 0 to 1.
- The sum of the squared residuals divided by the sum of the squared correlations is an estimate of model fit.
Analyzing the residuals means we need to extract only the upper right of the triangle them into an object. We can do this in steps.
grmsPAF2_resids <- psych::factor.residuals(GRMSr, grmsPAF2$loadings) #first extract the resids
grmsPAF2_resids <- as.matrix(grmsPAF2_resids[upper.tri(grmsPAF2_resids)]) #the object has the residuals in a single column
head(grmsPAF2_resids) [,1]
[1,] 0.05128890
[2,] -0.01969873
[3,] 0.03041703
[4,] -0.02971380
[5,] -0.06927144
[6,] -0.03556489One criteria of residual analysis is to see how many residuals there are that are greater than an absolute value of 0.05. The result will be a single column with TRUE if it is > |0.05| and false if it is smaller. The sum function will tell us how many TRUE responses are in the matrix. Further, we can write script to obtain the proportion of total number of residuals.
[1] 57[1] 0.19We learn that there are 57 residuals greater than the absolute value of 0.05. This represents 19% of the total number of residuals.
There are no hard rules about what proportion of residuals can be greater than 0.05. Field recommends that it stay below 50% (Field, 2012).
Another approach to analyzing residuals is to look at their mean. Because of the +/- valences, we need to square them (to eliminate the negative), take the average, then take the square root.
[1] 0.036While there are no clear guidelines to interpret these, one recommendation is to consider extracting more factors if the value is higher than 0.08 (Field, 2012).
Finally, we expect our residuals to be normally distributed. A histogram can help us inspect the distribution.
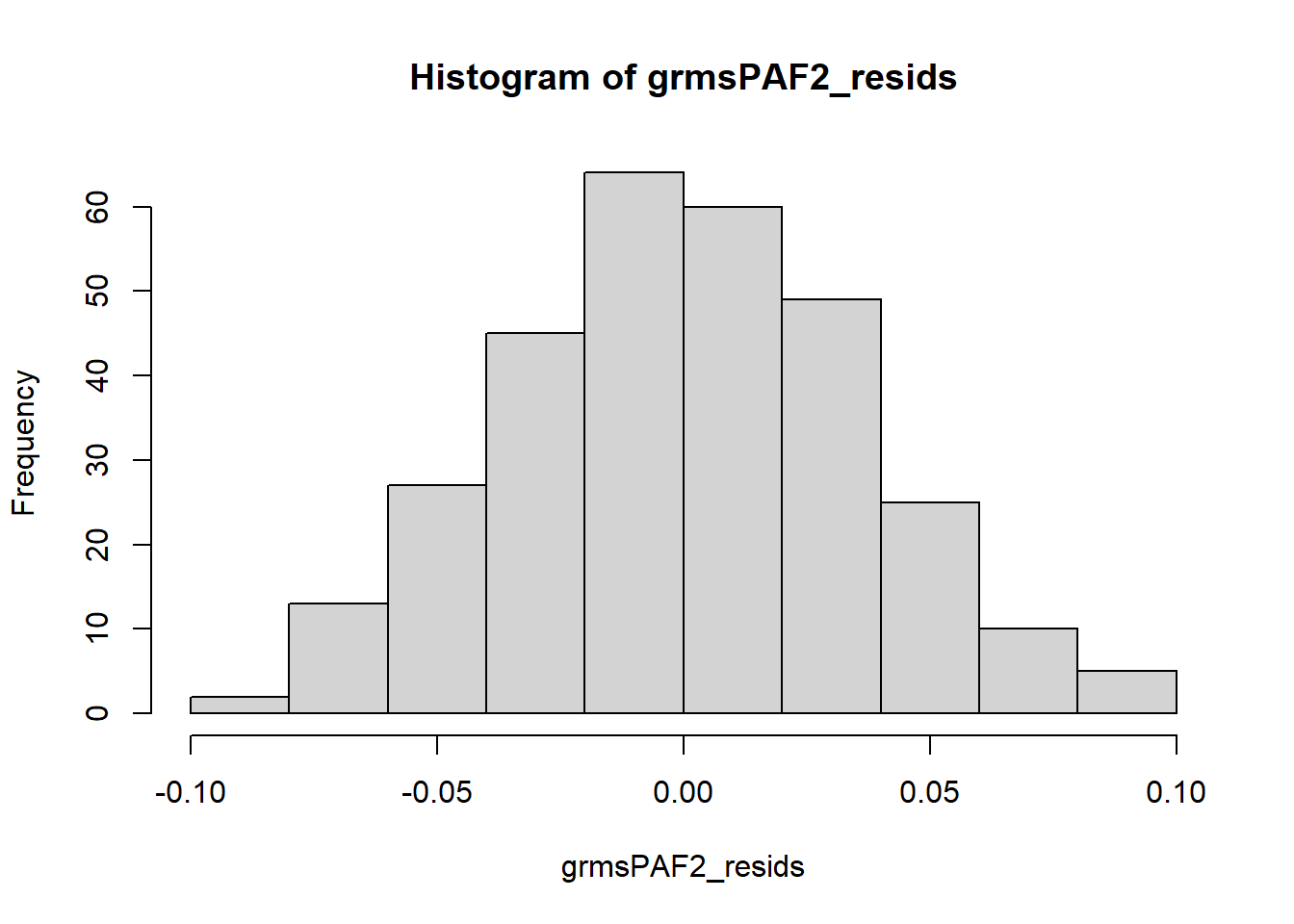
Not bad! It looks reasonably normal. No outliers.
9.5.2.2 Quick recap of how to evaluate the # of factors we extracted
- If fewer than 30 variables, the eigenvalue > 1 (Kaiser’s) critera is fine, so long as communalities are all > .70.
- If sample size > 250 and the average communalities are .6 or greater, this is acceptable
- When N > 200, the scree plot can be used.
- Regarding residuals:
- Fewer than 50% should have absolute values > 0.05.
- Model fit should be > 0.90.
9.5.3 Factor Rotation
Here’s a snip of our location in the PAF workflow.

The original solution of a principal components or principal axis factor analysis is a set of vectors that best account for the observed covariance or correlation matrix. Each additional component or factor accounts for progressively less and less variance. The solution is efficient (yay) but difficult to interpret (boo).
Thanks to Thurstone’s five rules toward a simple structure (circa 1947), interpretation of a matrix is facilitated by rotation (multiplying a matrix by a matrix of orthogonal vectors that preserve the communalities of each variable). Both the original matrix and the solution will be orthogonal.
Parsimony becomes a statistical consideration (an equation, in fact) and goal and is maximized when each variable has a 1.0 loading on one factor and the rest are zero.
Different rotation strategies emphasize different goals related to parsimony:
Quartimax seeks to maximize the notion of variable parsimony (each variable is associated with one factor) and permits the rotation toward a general factor (ignoring smaller factors). Varimax maximizes the variance of squared loadings taken over items instead of over factors and avoids a general factor.
Rotation improves the interpretation of the factor by maximizing the loading on each variable on one of the extracted factors while minimizing the loading on all other factors. Rotation works by changing the absolute values of the variables while keeping their differential values constant.
There are two big choices (to be made on theoretical grounds):
- Orthogonal rotation if you think that the factors are independent/unrelated.
- varimax is the most common orthogonal rotation
- Oblique rotation if you think that the factors are related/correlated.
- oblimin and promax are common oblique rotations
9.5.3.1 Orthogonal rotation
# grmsPAF2ORTH <- psych::fa(GRMSr, nfactors = 4, fm = 'pa', rotate =
# 'varimax')
grmsPAF2ORTH <- psych::fa(dfGRMS, nfactors = 4, fm = "pa", rotate = "varimax")
grmsPAF2ORTHFactor Analysis using method = pa
Call: psych::fa(r = dfGRMS, nfactors = 4, rotate = "varimax", fm = "pa")
Standardized loadings (pattern matrix) based upon correlation matrix
PA1 PA2 PA3 PA4 h2 u2 com
Obj1 0.49 0.14 0.16 0.04 0.29 0.71 1.4
Obj2 0.51 0.18 0.13 0.09 0.32 0.68 1.4
Obj3 0.45 0.14 0.15 0.07 0.25 0.75 1.5
Obj4 0.54 0.19 0.04 0.03 0.33 0.67 1.3
Obj5 0.47 0.15 0.19 -0.02 0.28 0.72 1.6
Obj6 0.39 0.05 0.06 0.26 0.22 0.78 1.8
Obj7 0.41 0.27 0.16 0.10 0.27 0.73 2.2
Obj8 0.52 0.23 0.03 -0.18 0.35 0.65 1.7
Obj9 0.38 0.07 0.19 -0.01 0.19 0.81 1.5
Obj10 0.44 0.06 0.06 0.12 0.22 0.78 1.2
Marg1 0.13 0.77 0.08 0.02 0.62 0.38 1.1
Marg2 0.13 0.53 0.30 0.15 0.41 0.59 1.9
Marg3 0.18 0.46 0.16 0.08 0.28 0.72 1.6
Marg4 0.26 0.45 -0.01 0.13 0.28 0.72 1.8
Marg5 0.23 0.49 0.16 0.07 0.33 0.67 1.7
Marg6 0.35 0.35 0.08 0.16 0.27 0.73 2.5
Marg7 0.14 0.38 0.07 0.10 0.18 0.82 1.5
Str1 0.16 0.16 0.55 -0.08 0.36 0.64 1.4
Str2 0.24 0.09 0.30 0.16 0.18 0.82 2.7
Str3 0.07 0.07 0.51 0.06 0.28 0.72 1.1
Str4 0.14 0.04 0.38 -0.03 0.17 0.83 1.3
Str5 0.11 0.09 0.36 0.16 0.18 0.82 1.8
Ang1 0.02 0.18 0.35 0.25 0.22 0.78 2.4
Ang2 0.05 0.20 0.06 0.62 0.43 0.57 1.2
Ang3 0.10 0.26 0.15 0.31 0.19 0.81 2.7
PA1 PA2 PA3 PA4
SS loadings 2.60 2.26 1.41 0.83
Proportion Var 0.10 0.09 0.06 0.03
Cumulative Var 0.10 0.19 0.25 0.28
Proportion Explained 0.37 0.32 0.20 0.12
Cumulative Proportion 0.37 0.68 0.88 1.00
Mean item complexity = 1.7
Test of the hypothesis that 4 factors are sufficient.
df null model = 300 with the objective function = 4.89 with Chi Square = 1217.51
df of the model are 206 and the objective function was 0.77
The root mean square of the residuals (RMSR) is 0.04
The df corrected root mean square of the residuals is 0.04
The harmonic n.obs is 259 with the empirical chi square 202.41 with prob < 0.56
The total n.obs was 259 with Likelihood Chi Square = 189.19 with prob < 0.79
Tucker Lewis Index of factoring reliability = 1.027
RMSEA index = 0 and the 90 % confidence intervals are 0 0.018
BIC = -955.52
Fit based upon off diagonal values = 0.97
Measures of factor score adequacy
PA1 PA2 PA3 PA4
Correlation of (regression) scores with factors 0.84 0.85 0.76 0.72
Multiple R square of scores with factors 0.71 0.72 0.58 0.52
Minimum correlation of possible factor scores 0.42 0.45 0.17 0.03Essentially, we have the same information as before, except that loadings are calculated after rotation (which adjusts the absolute values of the factor loadings while keeping their differential vales constant). Our communality and uniqueness values remain the same. The eigenvalues (SS loadings) should even out, but the proportion of variance explained and cumulative variance (28%) will remain the same.
The print.psych() function facilitates interpretation and prioritizes the information about which we care most:
- cut displays loadings above .3, this allows us to see
- if some items load on no factors
- if some items have cross-loadings (and their relative weights)
- sort reorders the loadings to make it clearer (considering ties, to the best of its ability) to which factor/scale it belongs
Factor Analysis using method = pa
Call: psych::fa(r = dfGRMS, nfactors = 4, rotate = "varimax", fm = "pa")
Standardized loadings (pattern matrix) based upon correlation matrix
item PA1 PA2 PA3 PA4 h2 u2 com
Obj4 4 0.54 0.33 0.67 1.3
Obj8 8 0.52 0.35 0.65 1.7
Obj2 2 0.51 0.32 0.68 1.4
Obj1 1 0.49 0.29 0.71 1.4
Obj5 5 0.47 0.28 0.72 1.6
Obj3 3 0.45 0.25 0.75 1.5
Obj10 10 0.44 0.22 0.78 1.2
Obj7 7 0.41 0.27 0.73 2.2
Obj6 6 0.39 0.22 0.78 1.8
Obj9 9 0.38 0.19 0.81 1.5
Marg1 11 0.77 0.62 0.38 1.1
Marg2 12 0.53 0.41 0.59 1.9
Marg5 15 0.49 0.33 0.67 1.7
Marg3 13 0.46 0.28 0.72 1.6
Marg4 14 0.45 0.28 0.72 1.8
Marg7 17 0.38 0.18 0.82 1.5
Marg6 16 0.35 0.35 0.27 0.73 2.5
Str1 18 0.55 0.36 0.64 1.4
Str3 20 0.51 0.28 0.72 1.1
Str4 21 0.38 0.17 0.83 1.3
Str5 22 0.36 0.18 0.82 1.8
Ang1 23 0.35 0.22 0.78 2.4
Str2 19 0.30 0.18 0.82 2.7
Ang2 24 0.62 0.43 0.57 1.2
Ang3 25 0.31 0.19 0.81 2.7
PA1 PA2 PA3 PA4
SS loadings 2.60 2.26 1.41 0.83
Proportion Var 0.10 0.09 0.06 0.03
Cumulative Var 0.10 0.19 0.25 0.28
Proportion Explained 0.37 0.32 0.20 0.12
Cumulative Proportion 0.37 0.68 0.88 1.00
Mean item complexity = 1.7
Test of the hypothesis that 4 factors are sufficient.
df null model = 300 with the objective function = 4.89 with Chi Square = 1217.51
df of the model are 206 and the objective function was 0.77
The root mean square of the residuals (RMSR) is 0.04
The df corrected root mean square of the residuals is 0.04
The harmonic n.obs is 259 with the empirical chi square 202.41 with prob < 0.56
The total n.obs was 259 with Likelihood Chi Square = 189.19 with prob < 0.79
Tucker Lewis Index of factoring reliability = 1.027
RMSEA index = 0 and the 90 % confidence intervals are 0 0.018
BIC = -955.52
Fit based upon off diagonal values = 0.97
Measures of factor score adequacy
PA1 PA2 PA3 PA4
Correlation of (regression) scores with factors 0.84 0.85 0.76 0.72
Multiple R square of scores with factors 0.71 0.72 0.58 0.52
Minimum correlation of possible factor scores 0.42 0.45 0.17 0.03In the unrotated solution, most variables loaded on the first factor. After rotation, there are four clear factors/scales. Further, there is clear (or at least reasonable) factor/scale membership for each item and few cross-loadings. As with the PAC in the previous lesson, Ang1 is not clearly loading on the Angry scale.
If this were a new scale and we had not yet established ideas for subscales, the next step would be to look back at the items, themselves, and try to name the scales/factors. If our scale construction included a priori/planned subscales, we would hope the items would where they were hypothesized to do so. As we noted with the Ang1 item, our simulated data nearly replicated the item membership onto the four scales that Lewis and Neville (J. A. Lewis & Neville, 2015) reported in the article.
- Assumptions of Beauty and Sexual Objectification
- Silenced and Marginalized
- Strong Woman Stereotype
- Angry Woman Stereotype
We can also create a figure of the result. Note the direction of the arrows from the factor (latent variable) to the items in PAF – in PCA the arrows went from item to component.
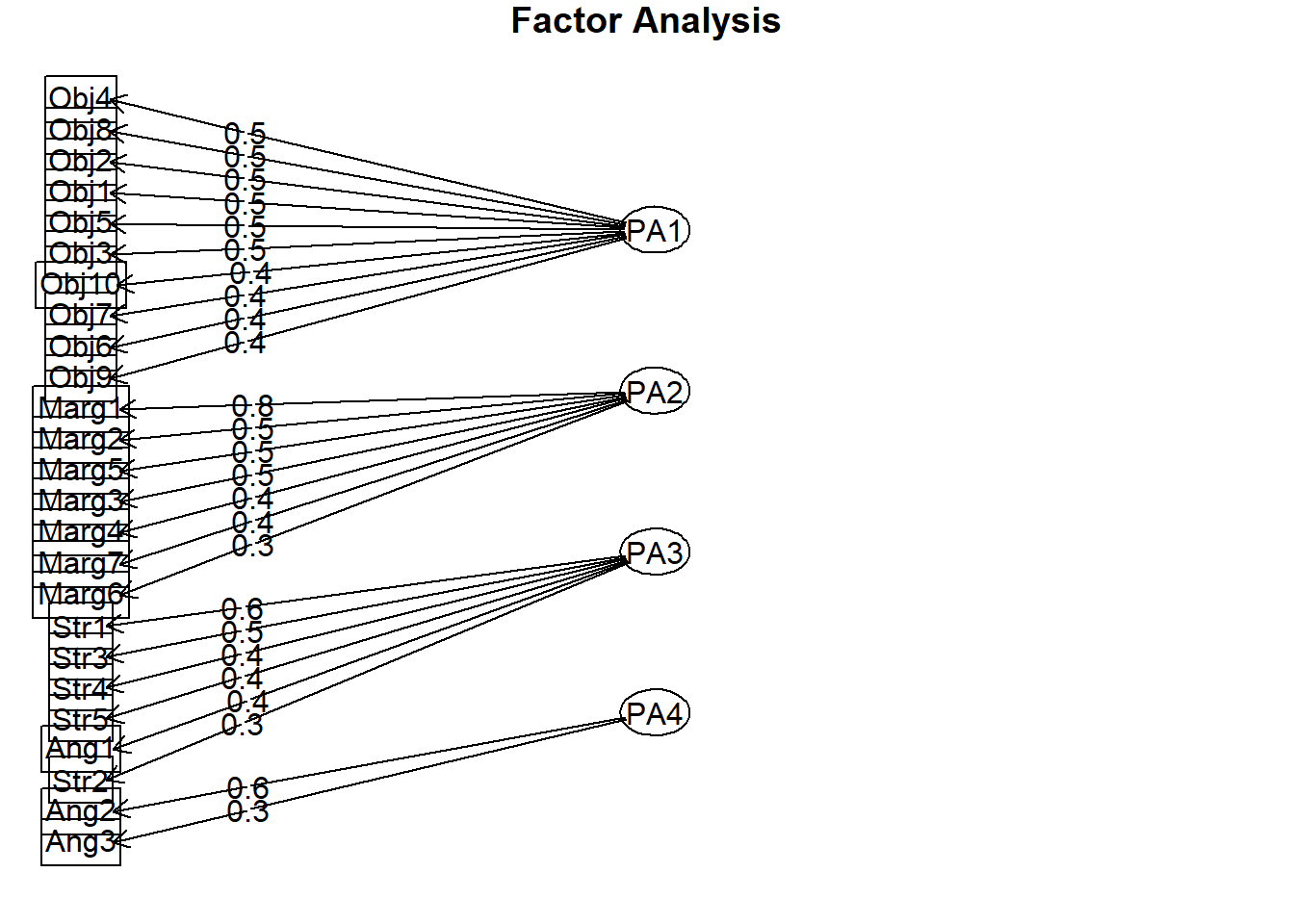
We can extract the factor loadings and write them to a table. This can be useful in preparing an APA style table for a manuscript or presentation.
# names(grmsPAF2ORTH)
pafORTH_table <- round(grmsPAF2ORTH$loadings, 3)
write.table(pafORTH_table, file = "pafORTH_table.csv", sep = ",", col.names = TRUE,
row.names = FALSE)
pafORTH_table
Loadings:
PA1 PA2 PA3 PA4
Obj1 0.495 0.144 0.160
Obj2 0.513 0.179 0.131
Obj3 0.452 0.140 0.147
Obj4 0.536 0.191
Obj5 0.469 0.154 0.189
Obj6 0.391 0.257
Obj7 0.408 0.265 0.164
Obj8 0.517 0.232 -0.177
Obj9 0.382 0.187
Obj10 0.442 0.122
Marg1 0.126 0.772
Marg2 0.126 0.534 0.296 0.151
Marg3 0.175 0.462 0.161
Marg4 0.256 0.446 0.130
Marg5 0.230 0.493 0.162
Marg6 0.345 0.348 0.157
Marg7 0.142 0.381 0.104
Str1 0.160 0.161 0.553
Str2 0.236 0.301 0.160
Str3 0.512
Str4 0.141 0.381
Str5 0.115 0.362 0.161
Ang1 0.182 0.354 0.254
Ang2 0.198 0.621
Ang3 0.104 0.258 0.154 0.307
PA1 PA2 PA3 PA4
SS loadings 2.600 2.257 1.414 0.830
Proportion Var 0.104 0.090 0.057 0.033
Cumulative Var 0.104 0.194 0.251 0.2849.5.3.2 Oblique rotation
Whereas the orthogonal rotation sought to maximize the independence/unrelatedness of the factors, an oblique rotation will allow them to be correlated. Researchers often explore both solutions but only report one.
# grmsPAF2obl <- psych::fa(GRMSr, nfactors = 4, fm = 'pa', rotate =
# 'oblimin')
grmsPAF2obl <- psych::fa(dfGRMS, nfactors = 4, fm = "pa", rotate = "oblimin")Loading required namespace: GPArotationFactor Analysis using method = pa
Call: psych::fa(r = dfGRMS, nfactors = 4, rotate = "oblimin", fm = "pa")
Standardized loadings (pattern matrix) based upon correlation matrix
PA1 PA2 PA3 PA4 h2 u2 com
Obj1 0.51 0.00 0.08 0.00 0.29 0.71 1.1
Obj2 0.53 0.02 0.04 0.05 0.32 0.68 1.0
Obj3 0.46 0.00 0.07 0.04 0.25 0.75 1.1
Obj4 0.56 0.05 -0.05 0.00 0.33 0.67 1.0
Obj5 0.47 0.02 0.12 -0.06 0.28 0.72 1.2
Obj6 0.43 -0.11 -0.02 0.25 0.22 0.78 1.8
Obj7 0.38 0.14 0.08 0.06 0.27 0.73 1.4
Obj8 0.53 0.15 -0.05 -0.22 0.35 0.65 1.5
Obj9 0.39 -0.05 0.14 -0.04 0.19 0.81 1.3
Obj10 0.48 -0.08 -0.02 0.10 0.22 0.78 1.2
Marg1 -0.03 0.81 -0.03 -0.02 0.62 0.38 1.0
Marg2 -0.01 0.49 0.22 0.12 0.41 0.59 1.5
Marg3 0.08 0.43 0.09 0.05 0.28 0.72 1.2
Marg4 0.20 0.40 -0.11 0.11 0.28 0.72 1.8
Marg5 0.14 0.45 0.08 0.03 0.33 0.67 1.3
Marg6 0.31 0.25 -0.02 0.13 0.27 0.73 2.3
Marg7 0.07 0.36 0.00 0.08 0.18 0.82 1.2
Str1 0.07 0.08 0.56 -0.12 0.36 0.64 1.2
Str2 0.21 -0.04 0.27 0.14 0.18 0.82 2.5
Str3 -0.01 -0.02 0.53 0.04 0.28 0.72 1.0
Str4 0.10 -0.04 0.39 -0.06 0.17 0.83 1.2
Str5 0.06 -0.01 0.35 0.14 0.18 0.82 1.4
Ang1 -0.07 0.10 0.33 0.24 0.22 0.78 2.1
Ang2 0.01 0.07 -0.02 0.64 0.43 0.57 1.0
Ang3 0.04 0.18 0.09 0.30 0.19 0.81 1.9
PA1 PA2 PA3 PA4
SS loadings 2.79 2.03 1.37 0.91
Proportion Var 0.11 0.08 0.05 0.04
Cumulative Var 0.11 0.19 0.25 0.28
Proportion Explained 0.39 0.29 0.19 0.13
Cumulative Proportion 0.39 0.68 0.87 1.00
With factor correlations of
PA1 PA2 PA3 PA4
PA1 1.00 0.46 0.34 0.17
PA2 0.46 1.00 0.32 0.27
PA3 0.34 0.32 1.00 0.19
PA4 0.17 0.27 0.19 1.00
Mean item complexity = 1.4
Test of the hypothesis that 4 factors are sufficient.
df null model = 300 with the objective function = 4.89 with Chi Square = 1217.51
df of the model are 206 and the objective function was 0.77
The root mean square of the residuals (RMSR) is 0.04
The df corrected root mean square of the residuals is 0.04
The harmonic n.obs is 259 with the empirical chi square 202.41 with prob < 0.56
The total n.obs was 259 with Likelihood Chi Square = 189.19 with prob < 0.79
Tucker Lewis Index of factoring reliability = 1.027
RMSEA index = 0 and the 90 % confidence intervals are 0 0.018
BIC = -955.52
Fit based upon off diagonal values = 0.97
Measures of factor score adequacy
PA1 PA2 PA3 PA4
Correlation of (regression) scores with factors 0.89 0.89 0.80 0.75
Multiple R square of scores with factors 0.79 0.79 0.65 0.57
Minimum correlation of possible factor scores 0.59 0.58 0.30 0.14We can make it a little easier to interpret by removing all factor loadings below .30.
Factor Analysis using method = pa
Call: psych::fa(r = dfGRMS, nfactors = 4, rotate = "oblimin", fm = "pa")
Standardized loadings (pattern matrix) based upon correlation matrix
item PA1 PA2 PA3 PA4 h2 u2 com
Obj4 4 0.56 0.33 0.67 1.0
Obj8 8 0.53 0.35 0.65 1.5
Obj2 2 0.53 0.32 0.68 1.0
Obj1 1 0.51 0.29 0.71 1.1
Obj10 10 0.48 0.22 0.78 1.2
Obj5 5 0.47 0.28 0.72 1.2
Obj3 3 0.46 0.25 0.75 1.1
Obj6 6 0.43 0.22 0.78 1.8
Obj9 9 0.39 0.19 0.81 1.3
Obj7 7 0.38 0.27 0.73 1.4
Marg6 16 0.31 0.27 0.73 2.3
Marg1 11 0.81 0.62 0.38 1.0
Marg2 12 0.49 0.41 0.59 1.5
Marg5 15 0.45 0.33 0.67 1.3
Marg3 13 0.43 0.28 0.72 1.2
Marg4 14 0.40 0.28 0.72 1.8
Marg7 17 0.36 0.18 0.82 1.2
Str1 18 0.56 0.36 0.64 1.2
Str3 20 0.53 0.28 0.72 1.0
Str4 21 0.39 0.17 0.83 1.2
Str5 22 0.35 0.18 0.82 1.4
Ang1 23 0.33 0.22 0.78 2.1
Str2 19 0.18 0.82 2.5
Ang2 24 0.64 0.43 0.57 1.0
Ang3 25 0.19 0.81 1.9
PA1 PA2 PA3 PA4
SS loadings 2.79 2.03 1.37 0.91
Proportion Var 0.11 0.08 0.05 0.04
Cumulative Var 0.11 0.19 0.25 0.28
Proportion Explained 0.39 0.29 0.19 0.13
Cumulative Proportion 0.39 0.68 0.87 1.00
With factor correlations of
PA1 PA2 PA3 PA4
PA1 1.00 0.46 0.34 0.17
PA2 0.46 1.00 0.32 0.27
PA3 0.34 0.32 1.00 0.19
PA4 0.17 0.27 0.19 1.00
Mean item complexity = 1.4
Test of the hypothesis that 4 factors are sufficient.
df null model = 300 with the objective function = 4.89 with Chi Square = 1217.51
df of the model are 206 and the objective function was 0.77
The root mean square of the residuals (RMSR) is 0.04
The df corrected root mean square of the residuals is 0.04
The harmonic n.obs is 259 with the empirical chi square 202.41 with prob < 0.56
The total n.obs was 259 with Likelihood Chi Square = 189.19 with prob < 0.79
Tucker Lewis Index of factoring reliability = 1.027
RMSEA index = 0 and the 90 % confidence intervals are 0 0.018
BIC = -955.52
Fit based upon off diagonal values = 0.97
Measures of factor score adequacy
PA1 PA2 PA3 PA4
Correlation of (regression) scores with factors 0.89 0.89 0.80 0.75
Multiple R square of scores with factors 0.79 0.79 0.65 0.57
Minimum correlation of possible factor scores 0.59 0.58 0.30 0.14In this rotation, the Angry scale falls apart. As before, Ang1 is loading onto Strong. Additionally, Ang3 has factor loadings that fall below .30, and therefore do not appear in this table. Additionally, because our specification included “sort=TRUE”, the relative weights wiggled around and so the items are listed in a different order than in the orthogonal rotation.
The oblique rotation allows us to see the correlation between the factors/scales. This was not available in the orthogonal rotation because the assumption of the orthogonal/varimax rotation is that the scales/factors are uncorrelated; hence in the analysis they were fixed to 0.0. The correlations from our simulated data range from .19 to .46.
Of course there is always a little complexity. In oblique rotations, there is a distinction between the pattern matrix (which reports factor loadings and is comparable to the matrix we interpreted for the orthogonal rotation) and the structure matrix (takes into account the relationship between the factors/scales – it is a product of the pattern matrix and the matrix containing the correlation coefficients between the factors/scales). Most interpret the pattern matrix because it is simpler; however, it could be that values in the pattern matrix are suppressed because of relations between the factors. Therefore, the structure matrix can be a useful check and some editors will request it.
Obtaining the structure matrix requires two steps. First, multiply the factor loadings with the phi matrix.
PA1 PA2 PA3 PA4
Obj1 0.5351558 0.2587471 0.2578729 0.10672133
Obj2 0.5596959 0.2939415 0.2397101 0.15920737
Obj3 0.4931574 0.2456837 0.2386994 0.13178696
Obj4 0.5676937 0.2946510 0.1536862 0.09619880
Obj5 0.5143469 0.2639663 0.2797209 0.05320390
Obj6 0.4083011 0.1433380 0.1363673 0.28476763
Obj7 0.4891359 0.3627793 0.2697523 0.18376868
Obj8 0.5462750 0.3181931 0.1337799 -0.09863944
Obj9 0.4098436 0.1673842 0.2524221 0.04306615
Obj10 0.4526040 0.1614974 0.1403757 0.15874466
Marg1 0.3385023 0.7854134 0.2197285 0.18936979
Marg2 0.3164379 0.5904981 0.3994360 0.29125182
Marg3 0.3190254 0.5084002 0.2613340 0.19797897
Marg4 0.3686089 0.4872840 0.1082789 0.22714662
Marg5 0.3780702 0.5477661 0.2747713 0.19177240
Marg6 0.4417130 0.4228182 0.1911285 0.24703507
Marg7 0.2525475 0.4115888 0.1520707 0.19123240
Str1 0.2752766 0.2583504 0.5843472 0.02598261
Str2 0.3031342 0.1787399 0.3515298 0.21686734
Str3 0.1645811 0.1543190 0.5235449 0.13423477
Str4 0.1999438 0.1116093 0.3967457 0.02531912
Str5 0.1976930 0.1656974 0.3929920 0.21880162
Ang1 0.1344340 0.2417716 0.3896315 0.32188168
Ang2 0.1467619 0.2423578 0.1284210 0.65279494
Ang3 0.2088530 0.3073000 0.2225652 0.37115411Next, use Field’s (2012) function to produce the matrix.
# Field's function to produce the structure matrix
factor.structure <- function(fa, cut = 0.2, decimals = 2) {
structure.matrix <- psych::fa.sort(fa$loadings %*% fa$Phi)
structure.matrix <- data.frame(ifelse(abs(structure.matrix) < cut,
"", round(structure.matrix, decimals)))
return(structure.matrix)
}
factor.structure(grmsPAF2obl, cut = 0.3) PA1 PA2 PA3 PA4
Obj4 0.57
Obj2 0.56
Obj8 0.55 0.32
Obj1 0.54
Obj5 0.51
Obj3 0.49
Obj7 0.49 0.36
Obj10 0.45
Marg6 0.44 0.42
Obj9 0.41
Obj6 0.41
Marg1 0.34 0.79
Marg2 0.32 0.59 0.4
Marg5 0.38 0.55
Marg3 0.32 0.51
Marg4 0.37 0.49
Marg7 0.41
Str1 0.58
Str3 0.52
Str4 0.4
Str5 0.39
Ang1 0.39 0.32
Str2 0.3 0.35
Ang2 0.65
Ang3 0.31 0.37Here we see some instability. Marg6 had cross-loadings with two scales and “hopped” membership onto Objectification. All three Ang items are showing factor loadings on their own scale. However, Ang1 is still loading on Strong and Ang3 has some cross-loading.
9.5.4 Factor Scores
Factor scores (PA scores) can be created for each case (row) on each factor (column). These can be used to assess the relative standing of one person on the construct/variable to another. We can also use them in regression (in place of means or sums) when groups of predictors correlate so highly that there is multicollinearity.
Computation involves multiplying an individual’s item-level response by the factor loadings we obtained through the PAF process. The results will be one score per factor for each row/case.
# in all of this, don't forget to be specifying the datset that has
# the reverse-coded item replaced
grmsPAF2obl <- psych::fa(dfGRMS, nfactors = 4, fm = "pa", rotate = "oblimin",
scores = TRUE)
head(grmsPAF2obl$scores, 10) #shows us only the first 10 (of N = 2571) PA1 PA2 PA3 PA4
[1,] -0.8113951 -1.2471438 0.12524275 -0.5260185
[2,] 0.2984396 -0.7314827 0.50376631 0.2511270
[3,] 0.3834222 0.4035418 0.18143350 1.0737292
[4,] -0.9982416 -1.1583980 -0.01836819 -1.4226140
[5,] -0.1985534 0.4507445 -0.78705628 0.1813746
[6,] -0.4233586 0.3917061 -0.17730679 0.7556499
[7,] 0.2528621 0.4465398 -0.78836577 -0.4751612
[8,] -1.3823984 -0.5908492 0.36410712 0.5085523
[9,] -0.5534479 -1.2460939 -0.65935346 0.4168911
[10,] 0.1212895 -0.4771782 -0.60054957 0.1698606To bring this full circle, we can see the correlation of the factor scores; the pattern maps onto what we saw previously in the correlations between factors in the oblique rotation.
Call:psych::corr.test(x = dfGRMS[c("PA1", "PA2", "PA3", "PA4")])
Correlation matrix
PA1 PA2 PA3 PA4
PA1 1.00 0.58 0.48 0.28
PA2 0.58 1.00 0.45 0.41
PA3 0.48 0.45 1.00 0.33
PA4 0.28 0.41 0.33 1.00
Sample Size
[1] 259
Probability values (Entries above the diagonal are adjusted for multiple tests.)
PA1 PA2 PA3 PA4
PA1 0 0 0 0
PA2 0 0 0 0
PA3 0 0 0 0
PA4 0 0 0 0
To see confidence intervals of the correlations, print with the short=FALSE optionWe can extract the factor loadings and write them to a table. This can be useful in preparing an APA style table for a manuscript or presentation.
# names(grmsPAF2obl)
pafOBL_table <- round(grmsPAF2obl$loadings, 3)
write.table(pafOBL_table, file = "pafOBL_table.csv", sep = ",", col.names = TRUE,
row.names = FALSE)
pafOBL_table
Loadings:
PA1 PA2 PA3 PA4
Obj1 0.508
Obj2 0.526
Obj3 0.463
Obj4 0.563
Obj5 0.473 0.123
Obj6 0.426 -0.114 0.246
Obj7 0.385 0.141
Obj8 0.535 0.146 -0.220
Obj9 0.391 0.142
Obj10 0.479 0.102
Marg1 0.811
Marg2 0.492 0.223 0.117
Marg3 0.429
Marg4 0.202 0.400 -0.108 0.106
Marg5 0.136 0.451
Marg6 0.310 0.250 0.130
Marg7 0.356
Str1 0.558 -0.116
Str2 0.206 0.266 0.140
Str3 0.526
Str4 0.388
Str5 0.348 0.144
Ang1 0.103 0.334 0.241
Ang2 0.635
Ang3 0.178 0.298
PA1 PA2 PA3 PA4
SS loadings 2.523 1.762 1.190 0.794
Proportion Var 0.101 0.070 0.048 0.032
Cumulative Var 0.101 0.171 0.219 0.251We can also obtain a figure of this PAF with oblique rotation.
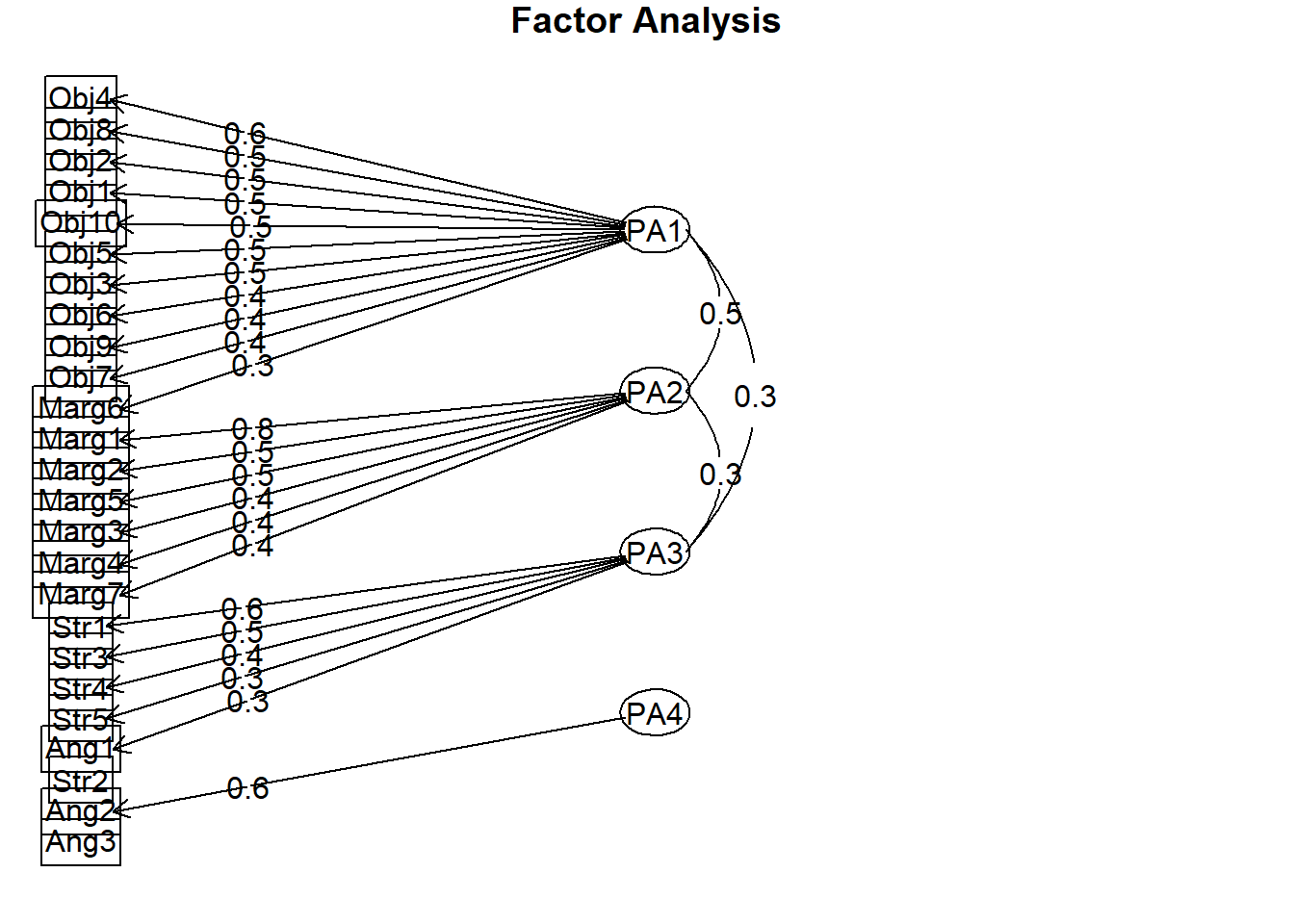
9.6 APA Style Results
Results
The dimensionality of the 25 items from the Gendered Racial Microaggressions Scale for Black Women was analyzed using principal axis factoring. First, data screening were conducted to determine the suitability of the data for principal axis factoring. The Kaiser-Meyer-Olkin measure of sampling adequacy (KMO; Kaiser, 1970) represents the ratio of the squared correlation between variables to the squared partial correlation between variables. KMO ranges from 0.00 to 1.00; values closer to 1.00 indicate that the patterns of correlations are relatively compact, and that factor analysis should yield distinct and reliable factors (Field, 2012). In our dataset, the KMO value was .85, indicating acceptable sampling adequacy. The Barlett’s Test of Sphericity examines whether the population correlation matrix resembles an identity matrix (Field, 2012). When the p value for the Bartlett’s test is < .05, we are fairly certain we have clusters of correlated variables. In our dataset, \(\chi^{2}(300)=1217.508, p < .001\), indicating the correlations between items are sufficiently large enough for principal axis factoring. The determinant of the correlation matrix alerts us to any issues of multicollinearity or singularity and should be larger than 0.00001. Our determinant was 0.0075, supporting the suitability of our data for analysis.
Four criteria were used to determine the number of factors to rotate: a priori theory, the scree test, the Eigenvalue-greater-than-one criteria, and the interpretability of the solution. Kaiser’s eigenvalue-greater-than-one criteria suggested two factors, and, in combination explained 28% of the variance. The scree plot showed an inflexion that justified retaining between one and four factors. A priori theory based on Lewis and Neville’s (2015) psychometric evaluation, suggested four factors. Based on the convergence of these decisions, four factors were extracted. We investigated each with orthogonal (varimax) and oblique (oblimin) procedures. Given the correspondence of the orthogonal solution with the original research, we selected this as our final model.
The rotated solution, as shown in Table 1 and Figure 1, yielded four interpretable factors, each listed with the proportion of variance accounted for: assumptions of beauty and sexual objectification (10%), silenced and marginalized (9%), strong woman stereotype (6%), and angry woman stereotype (3%).
Regarding the Table 1, I would include a table with all the values, bolding those with factor membership. This will be easy because we exported all those values to a .csv file.
9.6.1 Comparing FA and PCA
- FA derives a mathematical solution from which factors are estimated.
- Only FA can estimate underlying factors, but it relies on the various assumptions to be met.
- PCA decomposes the original data into a set of linear variates.
- This limits its concern to establishing which linear components exist within the data and how a particular variable might contribute to that component.
- Generally, FA and PCA result in similar solutions.
- When there are 30 or more variables and communalities are > .7 for all variables, different solutions are unlikely (Stevens, 2002).
- When there are < 20 variables and low communalities (< .4) different solutions are likely to emerge.
- Both are inferential statistics.
- Critics of PCA suggest
- “At best it is a common factor analysis with some error added and at worst an unrecognizable hodgepodge of things from which nothing can be determined” (Cliff, 1987, p. 349).
- PCA should never be described as FA and the resulting components should not be treated as reverently as true, latent variable, factors.
- To most of us (i.e., scientist-practitioners), the difference is largely from the algorithm used to derive the solutions. This is true for Field (Field, 2012) also, who uses the terms interchangeably. My take: use whichever you like, just be precise in the language describing what you did.
9.7 Going Back to the Future: What, then, is Omega?
Now that we’ve had an introduction to factor analysis, let’s revisit the \(\omega\) grouping of reliability estimates. In the context of psychometrics, it may be useful to think of factors as scales/subscales where g refers to the amount of variance in the general factor (or total scale score) and subcales to be items that have something in common that is separate from what is g.
Model-based estimates examine the correlations or covariances of the items and decompose the test variance into that which is:
- common to all items (g, a general factor),
- specific to some items (f, orthogonal group factors), and
- unique to each item (confounding s specific, and e error variance)
In the psych package
- \(\omega_{t}\) represents the total reliability of the test (\(\omega_{t}\)).
- In the psych package, this is calculated from a bifactor model where there is one general g factor (i.e., each item loads on the single general factor), one or more group factors (f), and an item-specific factor (s).
- \(\omega_{h}\) extracts a higher order factor from the correlation matrix of lower-level factors, then applies the Schmid and Leiman (1957) transformation to find the general loadings on the original items. Stated another way, it is a measure o f the general factor saturation (g; the amount of variance attributable to one common factor). The subscript “h” acknowledges the hierarchical nature of the approach.
- the \(\omega_{h}\) approach is exploratory and defined if there are three or more group factors (with only two group factors, the default is to assume they are equally important, hence the factor loadings of those subscales will be equal)
- Najera Catalan (Najera Catalan, 2019) suggests that \(\omega_{h}\) is the best measure of reliability when dealing with multiple dimensions.
- \(\omega_{g}\) is an estimate that uses a bifactor solution via the SEM package lavaan and tends to be a larger (because it forces all the cross-loadings of lower-level factors to be 0)
- \(\omega_{g}\) is confirmatory, requiring the specification of which variables load on each group factor
- psych::omegaSem() reports both EFA and CFA solutions
- We will use the psych::omegaSem() function.
Note that in our specification, we indicate there are two factors. We do not tell it (anywhere!) what items belong to what factors (think, subscales). One test will be to see if the items align with their respective factors.
# Because we added the factor scores to our df (and now it has more
# variables than just our items), I will estimate omegaSem with the
# correlation matrix; I will need to tell it the n.obs
psych::omegaSem(GRMSr, nfactors = 4, n.obs = 259)Warning in lav_model_vcov(lavmodel = lavmodel, lavsamplestats = lavsamplestats, : lavaan WARNING:
Could not compute standard errors! The information matrix could
not be inverted. This may be a symptom that the model is not
identified.
Call: psych::omegaSem(m = GRMSr, nfactors = 4, n.obs = 259)
Omega
Call: omegah(m = m, nfactors = nfactors, fm = fm, key = key, flip = flip,
digits = digits, title = title, sl = sl, labels = labels,
plot = plot, n.obs = n.obs, rotate = rotate, Phi = Phi, option = option,
covar = covar)
Alpha: 0.84
G.6: 0.86
Omega Hierarchical: 0.57
Omega H asymptotic: 0.66
Omega Total 0.86
Schmid Leiman Factor loadings greater than 0.2
g F1* F2* F3* F4* h2 u2 p2
Obj1 0.37 0.39 0.29 0.71 0.46
Obj2 0.40 0.40 0.32 0.68 0.49
Obj3 0.35 0.35 0.25 0.75 0.48
Obj4 0.37 0.43 0.33 0.67 0.42
Obj5 0.36 0.36 0.28 0.72 0.47
Obj6 0.27 0.32 0.23 0.22 0.78 0.33
Obj7 0.41 0.29 0.27 0.73 0.62
Obj8 0.35 0.41 -0.20 0.35 0.65 0.34
Obj9 0.28 0.30 0.19 0.81 0.41
Obj10 0.28 0.37 0.22 0.78 0.36
Marg1 0.53 0.58 0.62 0.38 0.46
Marg2 0.49 0.35 0.41 0.59 0.59
Marg3 0.42 0.30 0.28 0.72 0.62
Marg4 0.39 0.28 0.28 0.72 0.55
Marg5 0.46 0.32 0.33 0.67 0.64
Marg6 0.41 0.24 0.27 0.73 0.62
Marg7 0.33 0.25 0.18 0.82 0.59
Str1 0.34 0.48 0.36 0.64 0.31
Str2 0.29 0.23 0.18 0.82 0.46
Str3 0.25 0.46 0.28 0.72 0.23
Str4 0.21 0.34 0.17 0.83 0.25
Str5 0.25 0.30 0.18 0.82 0.36
Ang1 0.28 0.29 0.22 0.22 0.78 0.34
Ang2 0.27 0.61 0.44 0.56 0.16
Ang3 0.30 0.28 0.19 0.81 0.47
With Sums of squares of:
g F1* F2* F3* F4*
3.14 1.47 0.89 0.90 0.71
general/max 2.14 max/min = 2.07
mean percent general = 0.44 with sd = 0.13 and cv of 0.3
Explained Common Variance of the general factor = 0.44
The degrees of freedom are 206 and the fit is 0.77
The number of observations was 259 with Chi Square = 189.17 with prob < 0.79
The root mean square of the residuals is 0.04
The df corrected root mean square of the residuals is 0.04
RMSEA index = 0 and the 10 % confidence intervals are 0 0.018
BIC = -955.53
Compare this with the adequacy of just a general factor and no group factors
The degrees of freedom for just the general factor are 275 and the fit is 1.79
The number of observations was 259 with Chi Square = 445.32 with prob < 0.00000000034
The root mean square of the residuals is 0.09
The df corrected root mean square of the residuals is 0.09
RMSEA index = 0.049 and the 10 % confidence intervals are 0.041 0.057
BIC = -1082.81
Measures of factor score adequacy
g F1* F2* F3* F4*
Correlation of scores with factors 0.77 0.72 0.67 0.70 0.70
Multiple R square of scores with factors 0.60 0.52 0.44 0.49 0.49
Minimum correlation of factor score estimates 0.20 0.03 -0.11 -0.02 -0.01
Total, General and Subset omega for each subset
g F1* F2* F3* F4*
Omega total for total scores and subscales 0.86 0.78 0.72 0.59 0.44
Omega general for total scores and subscales 0.57 0.39 0.44 0.22 0.13
Omega group for total scores and subscales 0.19 0.39 0.28 0.37 0.31
The following analyses were done using the lavaan package
Omega Hierarchical from a confirmatory model using sem = 0.7
Omega Total from a confirmatory model using sem = 0.86
With loadings of
g F1* F2* F3* F4* h2 u2 p2
Obj1 0.38 0.39 0.30 0.70 0.48
Obj2 0.42 0.37 0.31 0.69 0.57
Obj3 0.37 0.32 0.24 0.76 0.57
Obj4 0.37 0.42 0.31 0.69 0.44
Obj5 0.36 0.38 0.28 0.72 0.46
Obj6 0.31 0.25 0.16 0.84 0.60
Obj7 0.46 0.26 0.28 0.72 0.76
Obj8 0.31 0.45 0.30 0.70 0.32
Obj9 0.28 0.31 0.17 0.83 0.46
Obj10 0.28 0.35 0.21 0.79 0.37
Marg1 0.54 0.54 0.58 0.42 0.50
Marg2 0.58 0.22 0.39 0.61 0.86
Marg3 0.46 0.28 0.29 0.71 0.73
Marg4 0.45 0.23 0.25 0.75 0.81
Marg5 0.53 0.23 0.33 0.67 0.85
Marg6 0.49 0.26 0.74 0.92
Marg7 0.37 0.21 0.18 0.82 0.76
Str1 0.36 0.40 0.29 0.71 0.45
Str2 0.34 0.23 0.17 0.83 0.68
Str3 0.27 0.50 0.32 0.68 0.23
Str4 0.20 0.41 0.21 0.79 0.19
Str5 0.31 0.22 0.14 0.86 0.69
Ang1 0.33 0.22 0.16 0.84 0.68
Ang2 0.35 0.69 0.60 0.40 0.20
Ang3 0.39 0.18 0.82 0.85
With sum of squared loadings of:
g F1* F2* F3* F4*
3.83 1.28 0.56 0.72 0.50
The degrees of freedom of the confirmatory model are 250 and the fit is 263.6354 with p = 0.264761
general/max 2.98 max/min = 2.55
mean percent general = 0.58 with sd = 0.22 and cv of 0.37
Explained Common Variance of the general factor = 0.56
Measures of factor score adequacy
g F1* F2* F3* F4*
Correlation of scores with factors 0.86 0.75 0.65 0.69 0.77
Multiple R square of scores with factors 0.75 0.56 0.42 0.48 0.59
Minimum correlation of factor score estimates 0.49 0.13 -0.16 -0.05 0.19
Total, General and Subset omega for each subset
g F1* F2* F3* F4*
Omega total for total scores and subscales 0.86 0.78 0.74 0.60 0.51
Omega general for total scores and subscales 0.70 0.43 0.56 0.28 0.22
Omega group for total scores and subscales 0.16 0.35 0.19 0.33 0.29
To get the standard sem fit statistics, ask for summary on the fitted objectThere’s a ton of output! How do we make sense of it?
First, excepting for the Angry scale (noted before), our items aligned reasonably with their respective factors (subscales).
Second, we can interpret our results. Like alpha, the omegas range from 0 to 1, where values closer to 1 represent good reliability (Najera Catalan, 2019). For unidimensional measures, \(\omega_{t}\) values above 0.80 seem to be an indicator of good reliability. For multidimensional measures with well-defined dimensions we strive for \(\omega_{h}\) values above 0.65 (and \(\omega_{t}\) > 0.8). These recommendations are based on a Monte Carlo study that examined a host of reliability indicators and how their values corresponded with accurate predictions of poverty status. With this in mind, let’s examine the output related to our simulated research vignette.
Let’s examine the output in the lower portion where the values are “from a confirmatory model using sem.”
Omega is a reliability estimate for factor analysis that represents the proportion of variance in the GRMS scale attributable to common variance (rather than error). The omega for the total reliability of the test (\(\omega_{t}\); which included the general factors and the subscale factors) was .86, meaning that 86% of the variance in the total scale is due to the factors and 14% (100% - 86%) is attributable to error.
Omega hierarchical (\(\omega_{h}\)) estimates are the proportion of variance in the GRMS score attributable to the general factor, which in effect treats the subscales as error. \(\omega_{h}\) for the the GRMS total scale was .70 A quick calculation with \(\omega_{h}\) (.70) and \(\omega_{t}\) (.86; .70/.86 = .81) lets us know that that 81% of the reliable variance in the GRMS total scale is attributable to the general factor.
[1] 0.8139535Amongst the output is the Cronbach’s alpha coefficient (.84). Lewis and Neville (2015) did not report omega results. They reported an alpha of .92 for the version of the GRMS that assessed stress appraisal.
9.8 Comparing PFA to Item Analysis and PCA
In the lesson on PCA, we began a table that compared our item analysis (item corrected-total correlations with item-other scale correlations) and PCA results (both orthogonal and oblique). Let’s now add our PAF results (both orthogonal and oblique).
In the prior lecture, I saved the file as both .rds and .csv objects. I will bring back in the .rds object and add to it.
Factor Analysis using method = pa
Call: psych::fa(r = dfGRMS, nfactors = 4, rotate = "varimax", fm = "pa")
Standardized loadings (pattern matrix) based upon correlation matrix
PA1 PA2 PA3 PA4 h2 u2 com
Obj1 0.49 0.14 0.16 0.04 0.29 0.71 1.4
Obj2 0.51 0.18 0.13 0.09 0.32 0.68 1.4
Obj3 0.45 0.14 0.15 0.07 0.25 0.75 1.5
Obj4 0.54 0.19 0.04 0.03 0.33 0.67 1.3
Obj5 0.47 0.15 0.19 -0.02 0.28 0.72 1.6
Obj6 0.39 0.05 0.06 0.26 0.22 0.78 1.8
Obj7 0.41 0.27 0.16 0.10 0.27 0.73 2.2
Obj8 0.52 0.23 0.03 -0.18 0.35 0.65 1.7
Obj9 0.38 0.07 0.19 -0.01 0.19 0.81 1.5
Obj10 0.44 0.06 0.06 0.12 0.22 0.78 1.2
Marg1 0.13 0.77 0.08 0.02 0.62 0.38 1.1
Marg2 0.13 0.53 0.30 0.15 0.41 0.59 1.9
Marg3 0.18 0.46 0.16 0.08 0.28 0.72 1.6
Marg4 0.26 0.45 -0.01 0.13 0.28 0.72 1.8
Marg5 0.23 0.49 0.16 0.07 0.33 0.67 1.7
Marg6 0.35 0.35 0.08 0.16 0.27 0.73 2.5
Marg7 0.14 0.38 0.07 0.10 0.18 0.82 1.5
Str1 0.16 0.16 0.55 -0.08 0.36 0.64 1.4
Str2 0.24 0.09 0.30 0.16 0.18 0.82 2.7
Str3 0.07 0.07 0.51 0.06 0.28 0.72 1.1
Str4 0.14 0.04 0.38 -0.03 0.17 0.83 1.3
Str5 0.11 0.09 0.36 0.16 0.18 0.82 1.8
Ang1 0.02 0.18 0.35 0.25 0.22 0.78 2.4
Ang2 0.05 0.20 0.06 0.62 0.43 0.57 1.2
Ang3 0.10 0.26 0.15 0.31 0.19 0.81 2.7
PA1 PA2 PA3 PA4
SS loadings 2.60 2.26 1.41 0.83
Proportion Var 0.10 0.09 0.06 0.03
Cumulative Var 0.10 0.19 0.25 0.28
Proportion Explained 0.37 0.32 0.20 0.12
Cumulative Proportion 0.37 0.68 0.88 1.00
Mean item complexity = 1.7
Test of the hypothesis that 4 factors are sufficient.
df null model = 300 with the objective function = 4.89 with Chi Square = 1217.51
df of the model are 206 and the objective function was 0.77
The root mean square of the residuals (RMSR) is 0.04
The df corrected root mean square of the residuals is 0.04
The harmonic n.obs is 259 with the empirical chi square 202.41 with prob < 0.56
The total n.obs was 259 with Likelihood Chi Square = 189.19 with prob < 0.79
Tucker Lewis Index of factoring reliability = 1.027
RMSEA index = 0 and the 90 % confidence intervals are 0 0.018
BIC = -955.52
Fit based upon off diagonal values = 0.97
Measures of factor score adequacy
PA1 PA2 PA3 PA4
Correlation of (regression) scores with factors 0.84 0.85 0.76 0.72
Multiple R square of scores with factors 0.71 0.72 0.58 0.52
Minimum correlation of possible factor scores 0.42 0.45 0.17 0.03# names(grmsPAF2ORTH) I had to add 'unclass' to the loadings to
# render them into a df
pafORTH_loadings <- data.frame(unclass(grmsPAF2ORTH$loadings))
pafORTH_loadings$Items <- c("Obj1", "Obj2", "Obj3", "Obj4", "Obj5", "Obj6",
"Obj7", "Obj8", "Obj9", "Obj10", "Marg1", "Marg2", "Marg3", "Marg4",
"Marg5", "Marg6", "Marg7", "Strong1", "Strong2", "Strong3", "Strong4",
"Strong5", "Angry1", "Angry2", "Angry3") #Item names for joining (and to make sure we know which variable is which)
pafORTH_loadings <- dplyr::rename(pafORTH_loadings, PAF_OR_Obj = PA1, PAF_OR_Mar = PA2,
PAF_OR_Str = PA3, PAF_OR_Ang = PA4)
# I had to add 'unclass' to the loadings to render them into a df
GRMScomps <- dplyr::full_join(GRMScomps, pafORTH_loadings, by = "Items")
# Now adding the PAF oblique loadings
pafOBLQ_loadings <- data.frame(unclass(grmsPAF2obl$loadings)) #I had to add 'unclass' to the loadings to render them into a df
pafOBLQ_loadings$Items <- c("Obj1", "Obj2", "Obj3", "Obj4", "Obj5", "Obj6",
"Obj7", "Obj8", "Obj9", "Obj10", "Marg1", "Marg2", "Marg3", "Marg4",
"Marg5", "Marg6", "Marg7", "Strong1", "Strong2", "Strong3", "Strong4",
"Strong5", "Angry1", "Angry2", "Angry3")
# Item names for joining (and to make sure we know which variable is
# which)
pafOBLQ_loadings <- dplyr::rename(pafOBLQ_loadings, PAF_OB_Obj = PA1, PAF_OB_Mar = PA2,
PAF_OB_Str = PA3, PAF_OB_Ang = PA4)
# I had to add 'unclass' to the loadings to render them into a df
GRMScomps <- dplyr::full_join(GRMScomps, pafOBLQ_loadings, by = "Items")
# Writes the table to a .csv file where you can open it with Excel
# and format )
write.csv(GRMScomps, file = "GRMS_Comps.csv", sep = ",", row.names = FALSE,
col.names = TRUE)Warning in write.csv(GRMScomps, file = "GRMS_Comps.csv", sep = ",", row.names =
FALSE, : attempt to set 'col.names' ignoredWarning in write.csv(GRMScomps, file = "GRMS_Comps.csv", sep = ",", row.names =
FALSE, : attempt to set 'sep' ignoredBelow we can see the consistency across item analysis, PCA (orthogonal and oblique), and PAF (orthogonal and oblique) comparisons. The results were consistent across the analyses, pointing only to problems with the Angry scale. Please note that the problems were with my simulated data and not the original data.
9.9 Practice Problems
In each of these lessons I provide suggestions for practice that allow you to select one or more problems that are graded in difficulty. In psychometrics, I strongly recommend that you have started with a dataset that has a minimum of three subscales and use it for all of the assignments in the OER. In any case, please plan to:
- Properly format and prepare the data.
- Conduct diagnostic tests to determine the suitability of the data for PAF
- Conduct tests to guide the decisions about number of factors to extract.
- Conduct orthogonal and oblique rotations (at least two each with different numbers of factor).
- Select one solution and preparing an APA style results section (with table and figure).
- Compare your results in light of any other psychometrics lessons where you have used this data (especially the item analysis and PCA lessons).
9.9.1 Problem #1: Play around with this simulation.
Copy the script for the simulation and then change (at least) one thing in the simulation to see how it impacts the results. If PAF is new to you, perhaps you just change the number in “set.seed(240311)” from 240311 to something else. Your results should parallel those obtained in the lecture, making it easier for you to check your work as you go. Don’t be surprised if the factor loadings wiggle around a little. Do try to make sense of them.
9.9.2 Problem #2: Conduct a PAF with another simulated set of data in the OER.
The second option involves utilizing one of the simulated datasets available in this OER. The last lesson in the OER contains three simulations that could be used for all of the statistics-based practice suggestions. Especially if you started with one of these examples in an earlier lesson, I highly recommend you continue with that.
Alternatively, Keum et al.’s Gendered Racial Microaggressions Scale for Asian American Women (Keum et al., 2018) will be used in the lessons on confirmatory factor analysis and Conover et al.’s (Conover et al., 2017) Ableist Microaggressions Scale is used in the lesson on invariance testing. Both of these would be suitable for the PCA and PAF homework assignments.
9.9.3 Problem #3: Try something entirely new.
Using data for which you have permission and access (e.g., IRB approved data you have collected or from your lab; data you simulate from a published article; data from the ReCentering Psych Stats survey described in the Qualtrics lesson, or data from an open science repository), complete a PAF analysis. The data should allow for at least three factors/subscales.
9.9.4 Grading Rubric
Using the lecture and workflow (chart) as a guide, please work through all the steps listed in the proposed assignment/grading rubric.
| Assignment Component | Points Possible | Points Earned |
|---|---|---|
| 1. Check and, if needed, format data | 5 | _____ |
| 2. Conduct and interpret the three diagnostic tests to determine if PAF is appropriate as an analysis (KMO, Bartlett’s, determinant). | 5 | _____ |
| 3. Determine how many factors to extract (e.g., scree plot, eigenvalues, theory). | 5 | _____ |
| 4. Conduct an orthogonal rotation with a minimum of two different numbers of factor extractions. | 5 | _____ |
| 5. Conduct an oblique rotation with a minimum of two different numbers of factor extractions. | 5 | _____ |
| 6. Determine which factor solution (e.g., orthogonal or oblique; which number of factors) you will suggest. | 5 | _____ |
| 7. APA style results section with table and figure of one of the solutions. | 5 | _____ |
| 8. Explanation to grader | 5 | _____ |
| Totals | 40 | _____ |
9.10 Homeworked Example
For more information about the data used in this homeworked example, please refer to the description and codebook located at the end of the introduction in first volume of ReCentering Psych Stats.
As a brief review, this data is part of an IRB-approved study, with consent to use in teaching demonstrations and to be made available to the general public via the open science framework. Hence, it is appropriate to use in this context. You will notice there are student- and teacher- IDs. These numbers are not actual student and teacher IDs, rather they were further re-identified so that they could not be connected to actual people.
Because this is an actual dataset, if you wish to work the problem along with me, you will need to download the ReC.rds data file from the Worked_Examples folder in the ReC_Psychometrics project on the GitHub.
The course evaluation items can be divided into three subscales:
- Valued by the student includes the items: ValObjectives, IncrUnderstanding, IncrInterest
- Traditional pedagogy includes the items: ClearResponsibilities, EffectiveAnswers, Feedback, ClearOrganization, ClearPresentation
- Socially responsive pedagogy includes the items: InclusvClassrm, EquitableEval, MultPerspectives, DEIintegration
In this homewoRked example I will use principal axis factoring in an exploratory factor analysis. My hope is that the results will support my solution of three dimensions: valued-by-the-student, traditional pedagogy, socially responsive pedagogy.
9.10.1 Check and, if needed, format data
With the next code I will create an item-level df with only the items used in the three scales.
library(tidyverse)
items <- big %>%
dplyr::select(ValObjectives, IncrUnderstanding, IncrInterest, ClearResponsibilities,
EffectiveAnswers, Feedback, ClearOrganization, ClearPresentation,
MultPerspectives, InclusvClassrm, DEIintegration, EquitableEval)Some of the analyses require non-missing data in the df.
Let’s check the structure of the data.
Classes 'data.table' and 'data.frame': 267 obs. of 12 variables:
$ ValObjectives : int 5 5 4 4 5 5 5 4 5 3 ...
$ IncrUnderstanding : int 2 3 4 3 4 5 2 4 5 4 ...
$ IncrInterest : int 5 3 4 2 4 5 3 2 5 1 ...
$ ClearResponsibilities: int 5 5 4 4 5 5 4 4 5 3 ...
$ EffectiveAnswers : int 5 3 5 3 5 4 3 2 3 3 ...
$ Feedback : int 5 3 4 2 5 5 4 4 5 2 ...
$ ClearOrganization : int 3 4 3 4 4 5 4 4 5 2 ...
$ ClearPresentation : int 4 4 4 2 5 4 4 4 5 2 ...
$ MultPerspectives : int 5 5 4 5 5 5 5 5 5 1 ...
$ InclusvClassrm : int 5 5 5 5 5 5 5 4 5 3 ...
$ DEIintegration : int 5 5 5 5 5 5 5 5 5 2 ...
$ EquitableEval : int 5 5 3 5 5 5 5 3 5 3 ...
- attr(*, ".internal.selfref")=<externalptr>
- attr(*, "na.action")= 'omit' Named int [1:43] 6 20 106 109 112 113 114 117 122 128 ...
..- attr(*, "names")= chr [1:43] "6" "20" "106" "109" ...9.10.2 Conduct and interpret the three diagnostic tests to determine if PAF is appropriate as an analysis (KMO, Bartlett’s, determinant)
9.10.2.1 KMO
The Kaiser-Meyer-Olkin (KMO) index is an index of sampling adequacy to let us know if the sample size is sufficient relative to the statistical characteristics of the data.
General criteria (1974, Kaiser):
- bare minimum of .5
- values between .5 and .7 as mediocre
- values above .9 are superb
Kaiser-Meyer-Olkin factor adequacy
Call: psych::KMO(r = items)
Overall MSA = 0.91
MSA for each item =
ValObjectives IncrUnderstanding IncrInterest
0.94 0.89 0.89
ClearResponsibilities EffectiveAnswers Feedback
0.91 0.93 0.94
ClearOrganization ClearPresentation MultPerspectives
0.94 0.91 0.93
InclusvClassrm DEIintegration EquitableEval
0.86 0.78 0.95 With a KMO of 0.91, the data seems appropriate to continue with the PCA.
9.10.2.2 Bartlett’s
Barlett’s test lets us know if the matrix is an identity matrix (i.e., where elements on the off-diagonal would be 0.0 and elements on the diagonal would be 1.0). Stated another way – items only correlate with “themselves” and not other variables.
When \(p < 0.05\) the matrix is not an identity matrix. That is, there are some relationships between variables that can be analyzed.
R was not square, finding R from data$chisq
[1] 1897.769
$p.value
[1] 0
$df
[1] 66The Barlett’s test, \(\chi^2(66) = 1897.77, p < 0.001\), indicating that the correlation matrix is not an identity matrix and, on that dimension, is suitable for analysis.
9.10.2.3 Determinant
Multicollinearity or singularity is diagnosed by the determinant. The determinant should be greater than 0.00001. If smaller, then there may be an issue with multicollinearity (variables that are too highly correlated) or singularity (variables that are perfectly correlated).
[1] 0.0006985496The value of the determinant is 0.0007; greater than 0.00001. We are not concerned with multicollinearity or singularity.
Summary from data screening:
Data screening were conducted to determine the suitability of the data for principal axis factoring. The Kaiser-Meyer-Olkin measure of sampling adequacy (KMO; Kaiser, 1970) represents the ratio of the squared correlation between variables to the squared partial correlation between variables. KMO ranges from 0.00 to 1.00; values closer to 1.00 indicate that the patterns of correlations are relatively compact, and that component analysis should yield distinct and reliable components (Field, 2012). In our dataset, the KMO value was 0.91, indicating acceptable sampling adequacy. The Barlett’s Test of Sphericity examines whether the population correlation matrix resembles an identity matrix (Field, 2012). When the p value for the Bartlett’s test is < .05, we are fairly certain we have clusters of correlated variables. In our dataset, \(\chi^2(66) = 1897.77, p < 0.001\) indicating the correlations between items are sufficiently large enough for principal components analysis. The determinant of the correlation matrix alerts us to any issues of multicollinearity or singularity and should be larger than 0.00001. Our determinant was 0.0007 and, again, indicated that our data was suitable for the analysis.
9.10.3 Determine how many components to extract (e.g., scree plot, eigenvalues, theory)
Specify fewer factors than number of items (12). For me it wouldn’t run unless it was 6 or fewer.
paf1 <- psych::fa(items, nfactors = 6, fm = "pa", max.iter = 100, rotate = "none") # using raw data and letting the length function automatically calculate the # factors as a function of how many columns in the raw datamaximum iteration exceededFactor Analysis using method = pa
Call: psych::fa(r = items, nfactors = 6, rotate = "none", max.iter = 100,
fm = "pa")
Standardized loadings (pattern matrix) based upon correlation matrix
PA1 PA2 PA3 PA4 PA5 PA6 h2 u2 com
ValObjectives 0.52 -0.07 0.16 0.05 0.05 0.10 0.31 0.688 1.3
IncrUnderstanding 0.65 -0.28 0.31 0.03 -0.04 -0.01 0.60 0.400 1.9
IncrInterest 0.74 -0.18 0.50 -0.18 0.13 -0.02 0.87 0.127 2.1
ClearResponsibilities 0.80 -0.09 -0.34 0.10 0.03 -0.06 0.77 0.226 1.4
EffectiveAnswers 0.78 -0.14 -0.13 0.05 0.09 -0.17 0.68 0.315 1.3
Feedback 0.74 0.05 -0.20 -0.12 0.22 0.05 0.65 0.347 1.4
ClearOrganization 0.78 -0.28 -0.13 0.12 -0.07 0.32 0.83 0.175 1.8
ClearPresentation 0.84 -0.21 0.01 0.12 -0.20 -0.11 0.82 0.182 1.3
MultPerspectives 0.81 0.30 -0.12 -0.40 -0.23 0.03 0.97 0.029 2.0
InclusvClassrm 0.64 0.41 0.18 0.21 -0.14 -0.08 0.67 0.327 2.3
DEIintegration 0.49 0.66 0.13 0.14 0.11 0.10 0.74 0.265 2.2
EquitableEval 0.69 0.09 -0.17 -0.02 0.13 -0.09 0.54 0.462 1.3
PA1 PA2 PA3 PA4 PA5 PA6
SS loadings 6.11 0.97 0.65 0.31 0.22 0.19
Proportion Var 0.51 0.08 0.05 0.03 0.02 0.02
Cumulative Var 0.51 0.59 0.64 0.67 0.69 0.70
Proportion Explained 0.72 0.11 0.08 0.04 0.03 0.02
Cumulative Proportion 0.72 0.84 0.91 0.95 0.98 1.00
Mean item complexity = 1.7
Test of the hypothesis that 6 factors are sufficient.
df null model = 66 with the objective function = 7.27 with Chi Square = 1897.77
df of the model are 9 and the objective function was 0.06
The root mean square of the residuals (RMSR) is 0.01
The df corrected root mean square of the residuals is 0.02
The harmonic n.obs is 267 with the empirical chi square 2.97 with prob < 0.97
The total n.obs was 267 with Likelihood Chi Square = 14.81 with prob < 0.096
Tucker Lewis Index of factoring reliability = 0.976
RMSEA index = 0.049 and the 90 % confidence intervals are 0 0.093
BIC = -35.47
Fit based upon off diagonal values = 1
Measures of factor score adequacy
PA1 PA2 PA3 PA4 PA5
Correlation of (regression) scores with factors 0.98 0.90 0.88 0.86 0.73
Multiple R square of scores with factors 0.97 0.81 0.77 0.74 0.54
Minimum correlation of possible factor scores 0.93 0.63 0.54 0.48 0.07
PA6
Correlation of (regression) scores with factors 0.68
Multiple R square of scores with factors 0.46
Minimum correlation of possible factor scores -0.08The eigenvalue-greater-than-one criteria suggests 1 factor (but the second factor has an SSloading of .97).
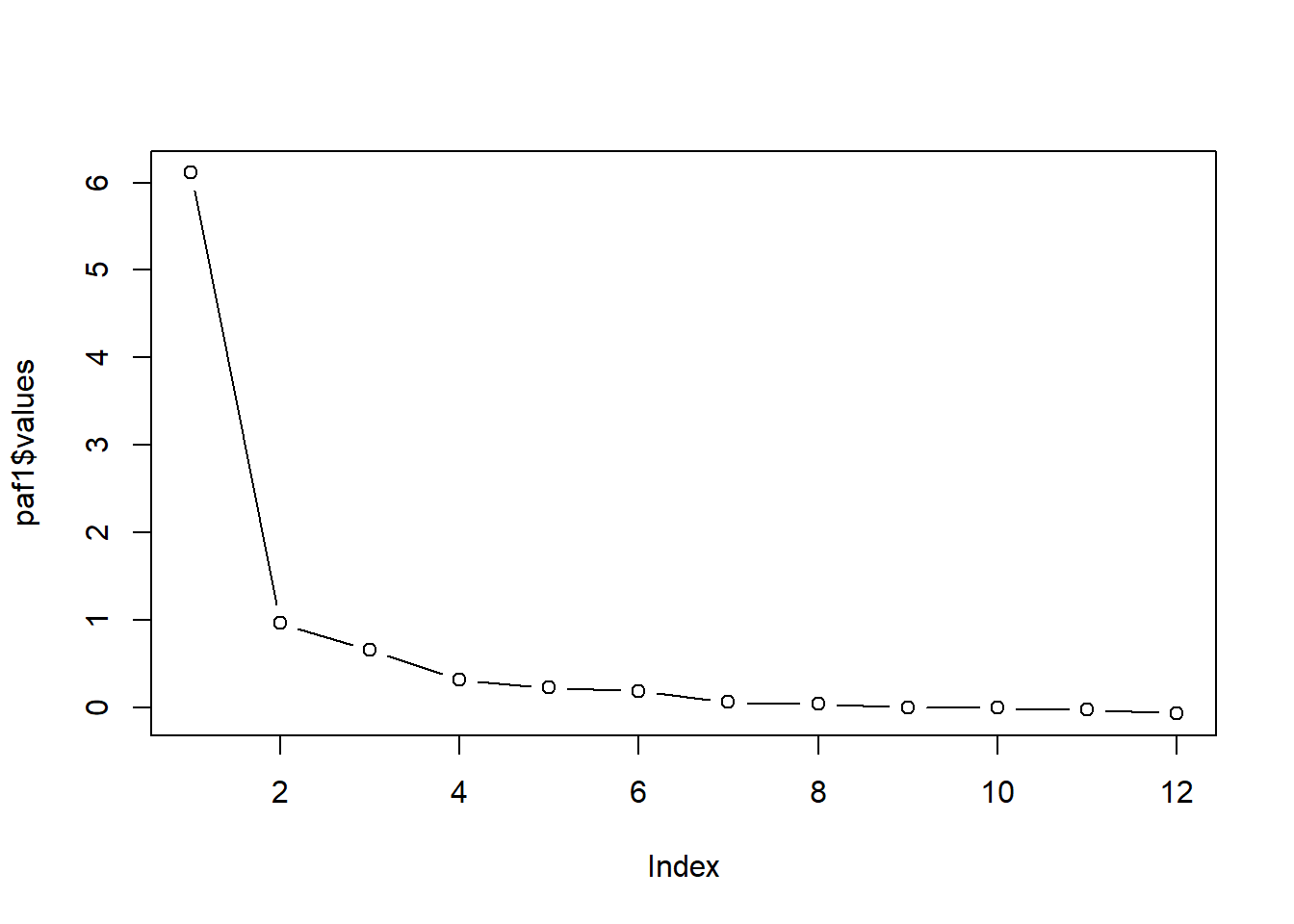 The scree plot looks like one factor.
The scree plot looks like one factor.
Ugh.
- I want 3 factors (we could think of this as a priori theory); would account for 64% of variance.
- Two could account for 59% of variance.
- Eigenvalues-greater-than-one criteria and scree plot suggests 1 or 3 (would account for 64% of variance)
Note: The lecture has more on evaluating communalities and uniquenesses and how this information can also inform the number of components we want to extract. Because it is easy to get lost (very lost) I will skip over this for now. If you were to create a measure and use PAF as an exploratory approach to understanding the dimensionality of an instrument, you would likely want to investigate further and report on these.
9.10.4 Conduct an orthogonal rotation with a minimum of two different factor extractions
An orthogonal two factor solution
Factor Analysis using method = minres
Call: psych::fa(r = items, nfactors = 2, rotate = "varimax")
Standardized loadings (pattern matrix) based upon correlation matrix
MR1 MR2 h2 u2 com
ValObjectives 0.48 0.21 0.27 0.73 1.4
IncrUnderstanding 0.67 0.12 0.46 0.54 1.1
IncrInterest 0.66 0.25 0.50 0.50 1.3
ClearResponsibilities 0.74 0.29 0.63 0.37 1.3
EffectiveAnswers 0.76 0.26 0.64 0.36 1.2
Feedback 0.63 0.38 0.54 0.46 1.7
ClearOrganization 0.79 0.17 0.65 0.35 1.1
ClearPresentation 0.83 0.23 0.75 0.25 1.2
MultPerspectives 0.58 0.55 0.64 0.36 2.0
InclusvClassrm 0.36 0.64 0.54 0.46 1.6
DEIintegration 0.08 0.86 0.75 0.25 1.0
EquitableEval 0.57 0.40 0.49 0.51 1.8
MR1 MR2
SS loadings 4.74 2.12
Proportion Var 0.39 0.18
Cumulative Var 0.39 0.57
Proportion Explained 0.69 0.31
Cumulative Proportion 0.69 1.00
Mean item complexity = 1.4
Test of the hypothesis that 2 factors are sufficient.
df null model = 66 with the objective function = 7.27 with Chi Square = 1897.77
df of the model are 43 and the objective function was 0.75
The root mean square of the residuals (RMSR) is 0.05
The df corrected root mean square of the residuals is 0.06
The harmonic n.obs is 267 with the empirical chi square 90.7 with prob < 0.000029
The total n.obs was 267 with Likelihood Chi Square = 194.26 with prob < 0.0000000000000000000041
Tucker Lewis Index of factoring reliability = 0.873
RMSEA index = 0.115 and the 90 % confidence intervals are 0.099 0.132
BIC = -46
Fit based upon off diagonal values = 0.99
Measures of factor score adequacy
MR1 MR2
Correlation of (regression) scores with factors 0.94 0.9
Multiple R square of scores with factors 0.89 0.8
Minimum correlation of possible factor scores 0.78 0.6Sorting the scores into a table can help see the results more clearly. The “cut = #” command will not show the factor scores for factor loading < .30. I would do this “to see”, but I would include all the values in an APA style table.
Factor Analysis using method = minres
Call: psych::fa(r = items, nfactors = 2, rotate = "varimax")
Standardized loadings (pattern matrix) based upon correlation matrix
item MR1 MR2 h2 u2 com
ClearPresentation 8 0.83 0.75 0.25 1.2
ClearOrganization 7 0.79 0.65 0.35 1.1
EffectiveAnswers 5 0.76 0.64 0.36 1.2
ClearResponsibilities 4 0.74 0.63 0.37 1.3
IncrUnderstanding 2 0.67 0.46 0.54 1.1
IncrInterest 3 0.66 0.50 0.50 1.3
Feedback 6 0.63 0.38 0.54 0.46 1.7
MultPerspectives 9 0.58 0.55 0.64 0.36 2.0
EquitableEval 12 0.57 0.40 0.49 0.51 1.8
ValObjectives 1 0.48 0.27 0.73 1.4
DEIintegration 11 0.86 0.75 0.25 1.0
InclusvClassrm 10 0.36 0.64 0.54 0.46 1.6
MR1 MR2
SS loadings 4.74 2.12
Proportion Var 0.39 0.18
Cumulative Var 0.39 0.57
Proportion Explained 0.69 0.31
Cumulative Proportion 0.69 1.00
Mean item complexity = 1.4
Test of the hypothesis that 2 factors are sufficient.
df null model = 66 with the objective function = 7.27 with Chi Square = 1897.77
df of the model are 43 and the objective function was 0.75
The root mean square of the residuals (RMSR) is 0.05
The df corrected root mean square of the residuals is 0.06
The harmonic n.obs is 267 with the empirical chi square 90.7 with prob < 0.000029
The total n.obs was 267 with Likelihood Chi Square = 194.26 with prob < 0.0000000000000000000041
Tucker Lewis Index of factoring reliability = 0.873
RMSEA index = 0.115 and the 90 % confidence intervals are 0.099 0.132
BIC = -46
Fit based upon off diagonal values = 0.99
Measures of factor score adequacy
MR1 MR2
Correlation of (regression) scores with factors 0.94 0.9
Multiple R square of scores with factors 0.89 0.8
Minimum correlation of possible factor scores 0.78 0.6F1: Includes everything else. F2: Includes 2 SCR items – DEIintegration, InclsvClssrm Also: EquitableEval MultPerspectives have high cross-loadings, but end up on the first factor
 Plotting these figures from the program can facilitate conceptual understanding of what is going on – and can be a “check” to your work.
Plotting these figures from the program can facilitate conceptual understanding of what is going on – and can be a “check” to your work.
In the lecture I made a “biggish deal” about PCA being components analysis and PAF being factor analysis. Although the two approaches can lead to similar results/conclusions, there are some significant differences “under the hood.” PCA can be thought of more as regression where the items predict the component. Consequently, the arrows went from the item to the component.
In PAF, the arrows will go from the factor to the item – because the factors (or latent variables) are assumed to predict the scores on the items (i.e., “depression” would predict how someone rates items that assess hopelessness, sleep, anhedonia, and so forth).
An orthogonal three factor solution
Factor Analysis using method = minres
Call: psych::fa(r = items, nfactors = 3, rotate = "varimax")
Standardized loadings (pattern matrix) based upon correlation matrix
MR1 MR3 MR2 h2 u2 com
ValObjectives 0.27 0.43 0.20 0.30 0.70 2.1
IncrUnderstanding 0.27 0.76 0.09 0.66 0.34 1.3
IncrInterest 0.27 0.75 0.25 0.69 0.31 1.5
ClearResponsibilities 0.84 0.24 0.17 0.79 0.21 1.2
EffectiveAnswers 0.67 0.41 0.18 0.64 0.36 1.8
Feedback 0.65 0.26 0.30 0.58 0.42 1.8
ClearOrganization 0.65 0.47 0.10 0.64 0.36 1.9
ClearPresentation 0.62 0.57 0.18 0.74 0.26 2.2
MultPerspectives 0.57 0.29 0.49 0.65 0.35 2.5
InclusvClassrm 0.28 0.30 0.63 0.56 0.44 1.9
DEIintegration 0.14 0.07 0.85 0.75 0.25 1.1
EquitableEval 0.60 0.23 0.33 0.52 0.48 1.9
MR1 MR3 MR2
SS loadings 3.37 2.39 1.77
Proportion Var 0.28 0.20 0.15
Cumulative Var 0.28 0.48 0.63
Proportion Explained 0.45 0.32 0.23
Cumulative Proportion 0.45 0.77 1.00
Mean item complexity = 1.8
Test of the hypothesis that 3 factors are sufficient.
df null model = 66 with the objective function = 7.27 with Chi Square = 1897.77
df of the model are 33 and the objective function was 0.29
The root mean square of the residuals (RMSR) is 0.02
The df corrected root mean square of the residuals is 0.03
The harmonic n.obs is 267 with the empirical chi square 19.55 with prob < 0.97
The total n.obs was 267 with Likelihood Chi Square = 75.2 with prob < 0.000039
Tucker Lewis Index of factoring reliability = 0.954
RMSEA index = 0.069 and the 90 % confidence intervals are 0.049 0.09
BIC = -109.18
Fit based upon off diagonal values = 1
Measures of factor score adequacy
MR1 MR3 MR2
Correlation of (regression) scores with factors 0.90 0.87 0.89
Multiple R square of scores with factors 0.82 0.76 0.79
Minimum correlation of possible factor scores 0.64 0.52 0.58Factor Analysis using method = minres
Call: psych::fa(r = items, nfactors = 3, rotate = "varimax")
Standardized loadings (pattern matrix) based upon correlation matrix
item MR1 MR3 MR2 h2 u2 com
ClearResponsibilities 4 0.84 0.79 0.21 1.2
EffectiveAnswers 5 0.67 0.41 0.64 0.36 1.8
Feedback 6 0.65 0.30 0.58 0.42 1.8
ClearOrganization 7 0.65 0.47 0.64 0.36 1.9
ClearPresentation 8 0.62 0.57 0.74 0.26 2.2
EquitableEval 12 0.60 0.33 0.52 0.48 1.9
MultPerspectives 9 0.57 0.49 0.65 0.35 2.5
IncrUnderstanding 2 0.76 0.66 0.34 1.3
IncrInterest 3 0.75 0.69 0.31 1.5
ValObjectives 1 0.43 0.30 0.70 2.1
DEIintegration 11 0.85 0.75 0.25 1.1
InclusvClassrm 10 0.63 0.56 0.44 1.9
MR1 MR3 MR2
SS loadings 3.37 2.39 1.77
Proportion Var 0.28 0.20 0.15
Cumulative Var 0.28 0.48 0.63
Proportion Explained 0.45 0.32 0.23
Cumulative Proportion 0.45 0.77 1.00
Mean item complexity = 1.8
Test of the hypothesis that 3 factors are sufficient.
df null model = 66 with the objective function = 7.27 with Chi Square = 1897.77
df of the model are 33 and the objective function was 0.29
The root mean square of the residuals (RMSR) is 0.02
The df corrected root mean square of the residuals is 0.03
The harmonic n.obs is 267 with the empirical chi square 19.55 with prob < 0.97
The total n.obs was 267 with Likelihood Chi Square = 75.2 with prob < 0.000039
Tucker Lewis Index of factoring reliability = 0.954
RMSEA index = 0.069 and the 90 % confidence intervals are 0.049 0.09
BIC = -109.18
Fit based upon off diagonal values = 1
Measures of factor score adequacy
MR1 MR3 MR2
Correlation of (regression) scores with factors 0.90 0.87 0.89
Multiple R square of scores with factors 0.82 0.76 0.79
Minimum correlation of possible factor scores 0.64 0.52 0.58F1: Traditional Pedagogy…+MultPerspectives F2: Valued-by-the-Student F3: SCRPed–the 2 items; Note: EquitableEval and MultPerspectivs have some cross-loading with first factor

9.10.5 Conduct an oblique rotation with a minimum of two different factor extractions
An oblique two factor solution
Factor Analysis using method = minres
Call: psych::fa(r = items, nfactors = 2, rotate = "oblimin")
Standardized loadings (pattern matrix) based upon correlation matrix
MR1 MR2 h2 u2 com
ValObjectives 0.50 0.05 0.27 0.73 1.0
IncrUnderstanding 0.73 -0.12 0.46 0.54 1.1
IncrInterest 0.69 0.03 0.50 0.50 1.0
ClearResponsibilities 0.77 0.04 0.63 0.37 1.0
EffectiveAnswers 0.80 0.00 0.64 0.36 1.0
Feedback 0.64 0.18 0.54 0.46 1.2
ClearOrganization 0.85 -0.11 0.65 0.35 1.0
ClearPresentation 0.89 -0.05 0.75 0.25 1.0
MultPerspectives 0.55 0.38 0.64 0.36 1.8
InclusvClassrm 0.30 0.55 0.54 0.46 1.5
DEIintegration -0.05 0.89 0.75 0.25 1.0
EquitableEval 0.57 0.22 0.49 0.51 1.3
MR1 MR2
SS loadings 5.32 1.54
Proportion Var 0.44 0.13
Cumulative Var 0.44 0.57
Proportion Explained 0.78 0.22
Cumulative Proportion 0.78 1.00
With factor correlations of
MR1 MR2
MR1 1.00 0.45
MR2 0.45 1.00
Mean item complexity = 1.2
Test of the hypothesis that 2 factors are sufficient.
df null model = 66 with the objective function = 7.27 with Chi Square = 1897.77
df of the model are 43 and the objective function was 0.75
The root mean square of the residuals (RMSR) is 0.05
The df corrected root mean square of the residuals is 0.06
The harmonic n.obs is 267 with the empirical chi square 90.7 with prob < 0.000029
The total n.obs was 267 with Likelihood Chi Square = 194.26 with prob < 0.0000000000000000000041
Tucker Lewis Index of factoring reliability = 0.873
RMSEA index = 0.115 and the 90 % confidence intervals are 0.099 0.132
BIC = -46
Fit based upon off diagonal values = 0.99
Measures of factor score adequacy
MR1 MR2
Correlation of (regression) scores with factors 0.97 0.91
Multiple R square of scores with factors 0.93 0.83
Minimum correlation of possible factor scores 0.86 0.65Factor Analysis using method = minres
Call: psych::fa(r = items, nfactors = 2, rotate = "oblimin")
Standardized loadings (pattern matrix) based upon correlation matrix
item MR1 MR2 h2 u2 com
ClearPresentation 8 0.89 0.75 0.25 1.0
ClearOrganization 7 0.85 0.65 0.35 1.0
EffectiveAnswers 5 0.80 0.64 0.36 1.0
ClearResponsibilities 4 0.77 0.63 0.37 1.0
IncrUnderstanding 2 0.73 0.46 0.54 1.1
IncrInterest 3 0.69 0.50 0.50 1.0
Feedback 6 0.64 0.54 0.46 1.2
EquitableEval 12 0.57 0.49 0.51 1.3
MultPerspectives 9 0.55 0.38 0.64 0.36 1.8
ValObjectives 1 0.50 0.27 0.73 1.0
DEIintegration 11 0.89 0.75 0.25 1.0
InclusvClassrm 10 0.55 0.54 0.46 1.5
MR1 MR2
SS loadings 5.32 1.54
Proportion Var 0.44 0.13
Cumulative Var 0.44 0.57
Proportion Explained 0.78 0.22
Cumulative Proportion 0.78 1.00
With factor correlations of
MR1 MR2
MR1 1.00 0.45
MR2 0.45 1.00
Mean item complexity = 1.2
Test of the hypothesis that 2 factors are sufficient.
df null model = 66 with the objective function = 7.27 with Chi Square = 1897.77
df of the model are 43 and the objective function was 0.75
The root mean square of the residuals (RMSR) is 0.05
The df corrected root mean square of the residuals is 0.06
The harmonic n.obs is 267 with the empirical chi square 90.7 with prob < 0.000029
The total n.obs was 267 with Likelihood Chi Square = 194.26 with prob < 0.0000000000000000000041
Tucker Lewis Index of factoring reliability = 0.873
RMSEA index = 0.115 and the 90 % confidence intervals are 0.099 0.132
BIC = -46
Fit based upon off diagonal values = 0.99
Measures of factor score adequacy
MR1 MR2
Correlation of (regression) scores with factors 0.97 0.91
Multiple R square of scores with factors 0.93 0.83
Minimum correlation of possible factor scores 0.86 0.65Curiously, there are fewer cross-loadings. F1 has everything except the 2 SCR items which are on F2.
 With the curved line and value between MR1 and MR2, this figure helps make “allowance” for components to correlate, clear. There was no such path on the orthogonal figures. This is because the rotation required the factors to be uncorrelated.
With the curved line and value between MR1 and MR2, this figure helps make “allowance” for components to correlate, clear. There was no such path on the orthogonal figures. This is because the rotation required the factors to be uncorrelated.
An oblique three factor solution
Factor Analysis using method = minres
Call: psych::fa(r = items, nfactors = 3, rotate = "oblimin")
Standardized loadings (pattern matrix) based upon correlation matrix
MR1 MR3 MR2 h2 u2 com
ValObjectives 0.14 0.40 0.10 0.30 0.70 1.4
IncrUnderstanding 0.03 0.81 -0.05 0.66 0.34 1.0
IncrInterest 0.00 0.78 0.13 0.69 0.31 1.1
ClearResponsibilities 0.97 -0.11 -0.04 0.79 0.21 1.0
EffectiveAnswers 0.68 0.18 -0.01 0.64 0.36 1.1
Feedback 0.69 0.00 0.15 0.58 0.42 1.1
ClearOrganization 0.64 0.27 -0.10 0.64 0.36 1.4
ClearPresentation 0.54 0.41 -0.02 0.74 0.26 1.9
MultPerspectives 0.53 0.07 0.36 0.65 0.35 1.8
InclusvClassrm 0.12 0.21 0.58 0.56 0.44 1.3
DEIintegration -0.01 -0.02 0.88 0.75 0.25 1.0
EquitableEval 0.63 -0.01 0.19 0.52 0.48 1.2
MR1 MR3 MR2
SS loadings 3.80 2.18 1.56
Proportion Var 0.32 0.18 0.13
Cumulative Var 0.32 0.50 0.63
Proportion Explained 0.50 0.29 0.21
Cumulative Proportion 0.50 0.79 1.00
With factor correlations of
MR1 MR3 MR2
MR1 1.00 0.65 0.43
MR3 0.65 1.00 0.31
MR2 0.43 0.31 1.00
Mean item complexity = 1.3
Test of the hypothesis that 3 factors are sufficient.
df null model = 66 with the objective function = 7.27 with Chi Square = 1897.77
df of the model are 33 and the objective function was 0.29
The root mean square of the residuals (RMSR) is 0.02
The df corrected root mean square of the residuals is 0.03
The harmonic n.obs is 267 with the empirical chi square 19.55 with prob < 0.97
The total n.obs was 267 with Likelihood Chi Square = 75.2 with prob < 0.000039
Tucker Lewis Index of factoring reliability = 0.954
RMSEA index = 0.069 and the 90 % confidence intervals are 0.049 0.09
BIC = -109.18
Fit based upon off diagonal values = 1
Measures of factor score adequacy
MR1 MR3 MR2
Correlation of (regression) scores with factors 0.96 0.93 0.91
Multiple R square of scores with factors 0.92 0.86 0.83
Minimum correlation of possible factor scores 0.84 0.71 0.65Factor Analysis using method = minres
Call: psych::fa(r = items, nfactors = 3, rotate = "oblimin")
Standardized loadings (pattern matrix) based upon correlation matrix
item MR1 MR3 MR2 h2 u2 com
ClearResponsibilities 4 0.97 0.79 0.21 1.0
Feedback 6 0.69 0.58 0.42 1.1
EffectiveAnswers 5 0.68 0.64 0.36 1.1
ClearOrganization 7 0.64 0.64 0.36 1.4
EquitableEval 12 0.63 0.52 0.48 1.2
ClearPresentation 8 0.54 0.41 0.74 0.26 1.9
MultPerspectives 9 0.53 0.36 0.65 0.35 1.8
IncrUnderstanding 2 0.81 0.66 0.34 1.0
IncrInterest 3 0.78 0.69 0.31 1.1
ValObjectives 1 0.40 0.30 0.70 1.4
DEIintegration 11 0.88 0.75 0.25 1.0
InclusvClassrm 10 0.58 0.56 0.44 1.3
MR1 MR3 MR2
SS loadings 3.80 2.18 1.56
Proportion Var 0.32 0.18 0.13
Cumulative Var 0.32 0.50 0.63
Proportion Explained 0.50 0.29 0.21
Cumulative Proportion 0.50 0.79 1.00
With factor correlations of
MR1 MR3 MR2
MR1 1.00 0.65 0.43
MR3 0.65 1.00 0.31
MR2 0.43 0.31 1.00
Mean item complexity = 1.3
Test of the hypothesis that 3 factors are sufficient.
df null model = 66 with the objective function = 7.27 with Chi Square = 1897.77
df of the model are 33 and the objective function was 0.29
The root mean square of the residuals (RMSR) is 0.02
The df corrected root mean square of the residuals is 0.03
The harmonic n.obs is 267 with the empirical chi square 19.55 with prob < 0.97
The total n.obs was 267 with Likelihood Chi Square = 75.2 with prob < 0.000039
Tucker Lewis Index of factoring reliability = 0.954
RMSEA index = 0.069 and the 90 % confidence intervals are 0.049 0.09
BIC = -109.18
Fit based upon off diagonal values = 1
Measures of factor score adequacy
MR1 MR3 MR2
Correlation of (regression) scores with factors 0.96 0.93 0.91
Multiple R square of scores with factors 0.92 0.86 0.83
Minimum correlation of possible factor scores 0.84 0.71 0.65 Again, pretty similar.
Again, pretty similar.
9.10.6 Determine which factor solution (e.g., orthogonal or oblique; which number of factors) you will suggest
From the oblique output we see that the correlations between the three subscales range from 0.25 to 0.58. These are high. Therefore, I will choose a 3-factor, oblique, solution.
9.10.7 APA style results section with table and figure of one of the solutions
The dimensionality of the 12 course evaluation items was analyzed using principal axis factoring (PAF). First, data were screened to determine the suitability of the data for this analyses. Data screening were conducted to determine the suitability of the data for this analyses. The Kaiser-Meyer-Olkin measure of sampling adequacy (KMO; Kaiser, 1970) represents the ratio of the squared correlation between variables to the squared partial correlation between variables. KMO ranges from 0.00 to 1.00; values closer to 1.00 indicate that the patterns of correlations are relatively compact, and that component analysis should yield distinct and reliable components (Field, 2012). In our dataset, the KMO value was 0.91, indicating acceptable sampling adequacy. The Barlett’s Test of Sphericity examines whether the population correlation matrix resembles an identity matrix (Field, 2012). When the p value for the Bartlett’s test is < .05, we are fairly certain we have clusters of correlated variables. In our dataset, \(\chi^2(66) = 1897.77, p < 0.001\) indicating the correlations between items are sufficiently large enough for principal components analysis. The determinant of the correlation matrix alerts us to any issues of multicollinearity or singularity and should be larger than 0.00001. Our determinant was 0.0007 and, again, indicated that our data was suitable for the analysis.
Four criteria were used to determine the number of components to extract: a priori theory, the scree test, the eigenvalue-greater-than-one criteria, and the interpretability of the solution. Kaiser’s eigenvalue-greater-than-one criteria suggested one component and explained 51% of the variance. The inflexion in the scree plot justified retaining one to three components. A priorili, we expected three factors – which would explain 63% of the variance. Correspondingly, we investigated two and three factor solutions with orthogonal (varimax) and oblique (oblimin) procedures. Given the significant correlations (ranging from .31 to .65) and the correspondence of items loading on the a priorili hypothesized components, we determined that an oblique, three-factor, solution was most appropriate.
The rotated solution, as shown in Table 1 and Figure 1, yielded three interpretable factors, each listed with the proportion of variance accounted for: traditional pedagogy (32%), valued-by-me (18%), and socially and culturally responsive pedagogy (13%).
Regarding the Table 1, I would include a table with ALL the values, bolding those with component membership. This is easy, though, because we can export it to a .csv file and
pafOBL3fb <- psych::fa(items, nfactors = 3, rotate = "oblimin")
paf_tableOBL3fb <- psych::print.psych(pafOBL3fb, sort = TRUE)Factor Analysis using method = minres
Call: psych::fa(r = items, nfactors = 3, rotate = "oblimin")
Standardized loadings (pattern matrix) based upon correlation matrix
item MR1 MR3 MR2 h2 u2 com
ClearResponsibilities 4 0.97 -0.11 -0.04 0.79 0.21 1.0
Feedback 6 0.69 0.00 0.15 0.58 0.42 1.1
EffectiveAnswers 5 0.68 0.18 -0.01 0.64 0.36 1.1
ClearOrganization 7 0.64 0.27 -0.10 0.64 0.36 1.4
EquitableEval 12 0.63 -0.01 0.19 0.52 0.48 1.2
ClearPresentation 8 0.54 0.41 -0.02 0.74 0.26 1.9
MultPerspectives 9 0.53 0.07 0.36 0.65 0.35 1.8
IncrUnderstanding 2 0.03 0.81 -0.05 0.66 0.34 1.0
IncrInterest 3 0.00 0.78 0.13 0.69 0.31 1.1
ValObjectives 1 0.14 0.40 0.10 0.30 0.70 1.4
DEIintegration 11 -0.01 -0.02 0.88 0.75 0.25 1.0
InclusvClassrm 10 0.12 0.21 0.58 0.56 0.44 1.3
MR1 MR3 MR2
SS loadings 3.80 2.18 1.56
Proportion Var 0.32 0.18 0.13
Cumulative Var 0.32 0.50 0.63
Proportion Explained 0.50 0.29 0.21
Cumulative Proportion 0.50 0.79 1.00
With factor correlations of
MR1 MR3 MR2
MR1 1.00 0.65 0.43
MR3 0.65 1.00 0.31
MR2 0.43 0.31 1.00
Mean item complexity = 1.3
Test of the hypothesis that 3 factors are sufficient.
df null model = 66 with the objective function = 7.27 with Chi Square = 1897.77
df of the model are 33 and the objective function was 0.29
The root mean square of the residuals (RMSR) is 0.02
The df corrected root mean square of the residuals is 0.03
The harmonic n.obs is 267 with the empirical chi square 19.55 with prob < 0.97
The total n.obs was 267 with Likelihood Chi Square = 75.2 with prob < 0.000039
Tucker Lewis Index of factoring reliability = 0.954
RMSEA index = 0.069 and the 90 % confidence intervals are 0.049 0.09
BIC = -109.18
Fit based upon off diagonal values = 1
Measures of factor score adequacy
MR1 MR3 MR2
Correlation of (regression) scores with factors 0.96 0.93 0.91
Multiple R square of scores with factors 0.92 0.86 0.83
Minimum correlation of possible factor scores 0.84 0.71 0.65pafOBL3fb_table <- round(pafOBL3fb$loadings, 3)
write.table(pafOBL3fb_table, file = "pafOBL3f_table.csv", sep = ",", col.names = TRUE,
row.names = FALSE)
pafOBL3fb_table
Loadings:
MR1 MR3 MR2
ValObjectives 0.140 0.398 0.103
IncrUnderstanding 0.810
IncrInterest 0.784 0.128
ClearResponsibilities 0.971 -0.108
EffectiveAnswers 0.676 0.182
Feedback 0.686 0.146
ClearOrganization 0.640 0.267
ClearPresentation 0.543 0.405
MultPerspectives 0.527 0.363
InclusvClassrm 0.121 0.207 0.580
DEIintegration 0.880
EquitableEval 0.629 0.185
MR1 MR3 MR2
SS loadings 3.283 1.758 1.339
Proportion Var 0.274 0.146 0.112
Cumulative Var 0.274 0.420 0.532